The what and why of Dagster#
Welcome to Dagster! If you’re here, you probably have questions about data, orchestration, Dagster, and how everything fits together.
Let’s start with the basics: What’s an orchestrator?
Orchestrators allow you to automatically execute a series of steps and track the results. They not only enable you and your team to see how long steps take to run or how they connect to other steps, but to understand when, where, and why things break.
Why do I need a data orchestrator?#
What if you’re working with data? Unlike generic orchestrators that may need to accommodate a variety of use cases, data orchestrators focus on building and managing data pipelines.
Data orchestrators allow you to automatically run, in the correct order, the steps in data pipelines that move, process, and transform data. A data orchestrator helps to ensure that your data assets - such as database tables, reports, language learning models, and so on - are accurate and up-to-date.
That being said, you might be asking yourself...
Why Dagster?#
Dagster models pipelines in terms of the data assets they produce and consume, which, by default, brings order and observability to your data platform. Assets in Dagster can model data produced by any system, such as dbt models, Snowflake tables, or even CSV files.
With Dagster, you declare functions in Python that you want to run and the data assets that those functions produce or update. For example, the following image is an example of a graph with several assets:
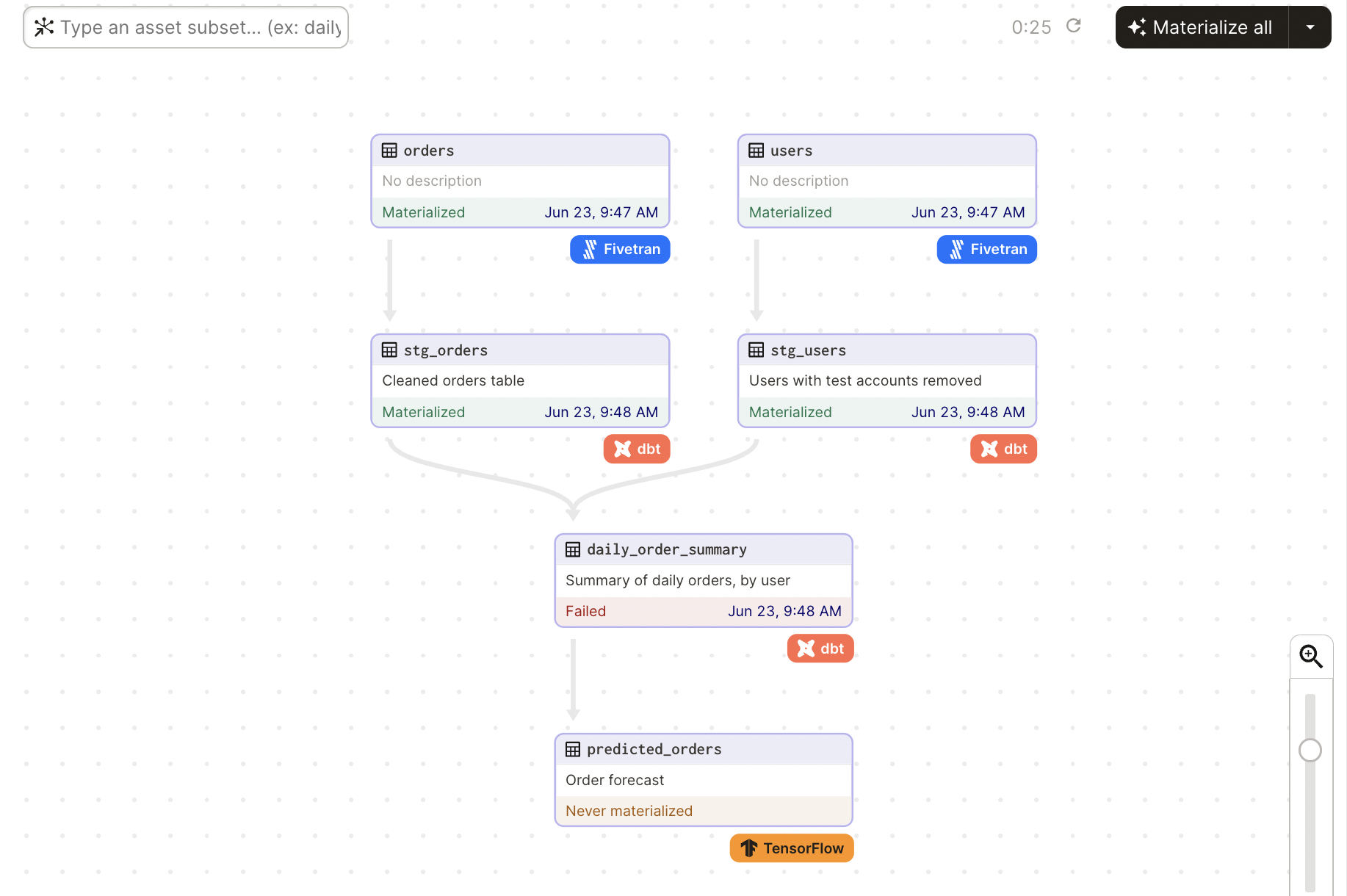
Dagster’s asset-centric approach to building data pipelines makes it easy to:
- Understand how an asset - like a database table or report - is produced. Everyone in your organization can understand the data lineage and how data assets relate to each other, even if they didn’t build the pipeline themselves.
- Determine if an asset is up to date. It’s easy to tell exactly why assets are out-of-date, whether it might be late upstream data or errors in code.
- Diagnose data quality issues. Building data quality checks into your pipelines is straightforward, and you can be notified automatically when data quality issues arise.
- Standardize best practices. Software-defined Assets (SDAs), the Dagster concept that produces data assets, are a unifying abstraction across all data teams. SDAs enable easier collaboration and rapid adoption of best practices such as domain-specific languages, continuous integration, local development, and testing.
- Simplify debugging. Every run and computation is tied to the goal of producing data, so debugging tools like logs are specific to the assets being produced. When something goes wrong, you can quickly identify the problematic asset, address it, and only need to re-execute that asset.
Dagster is built to be used at every stage of the data development lifecycle - local development, unit tests, integration tests, staging environments, all the way up to production.
Additionally, Dagster is accompanied by a sleek, modern, web-based UI. This ‘single pane of glass’ serves both engineers and the stakeholders they support: engineers can use the UI to inspect the data pipelines they create in code, and stakeholders can observe and monitor their data.
How does it work?#
If you want to try running Dagster yourself, check out the Dagster Quickstart.
How do I learn Dagster?#
Ready to dive in? Depending on your learning preferences, there are a few ways to get started:
- Dagster University - In-depth, step-by-step courses with quizzes and practice problems focusing on building in Dagster.
- Tutorial - Not as lengthy or detailed as Dagster University, the tutorial focuses on building a small data pipeline that retrieves data from HackerNews.
- Concepts - Detailed information about Dagster’s core concepts.
- Guides - Step-by-step guides for completing specific tasks with Dagster.