Welcome to Dagster
Dagster is a data orchestrator built for data engineers, with integrated lineage, observability, a declarative programming model, and best-in-class testability.
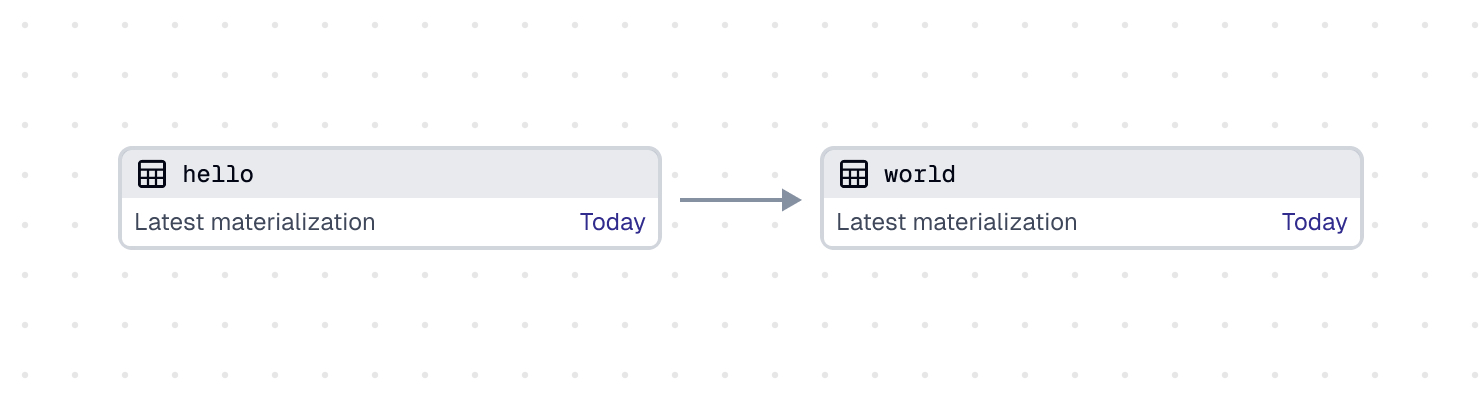
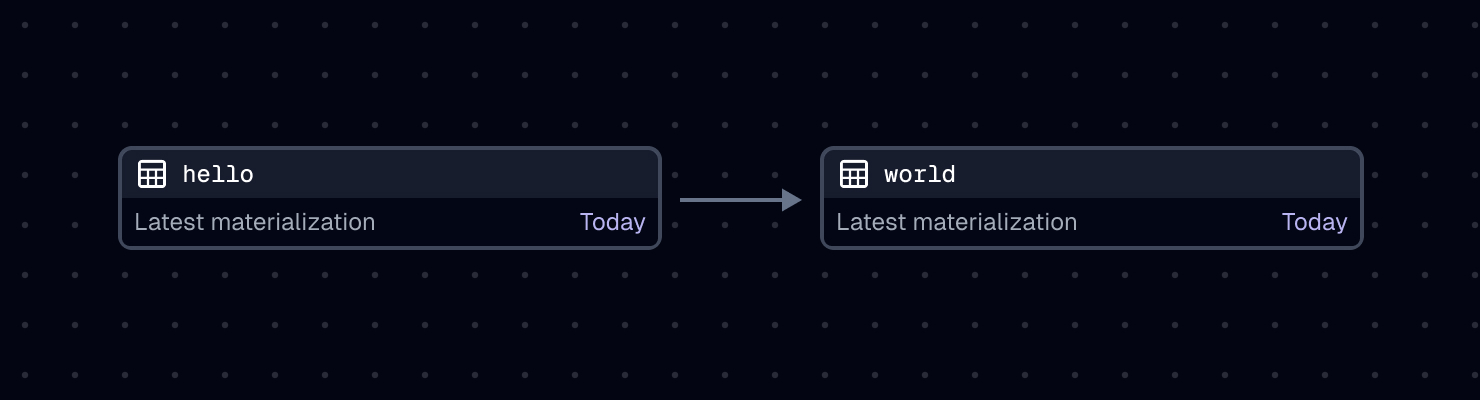
defs/assets.py
import dagster as dg
@dg.asset
def hello(context: dg.AssetExecutionContext):
context.log.info("Hello!")
@dg.asset(deps=[hello])
def world(context: dg.AssetExecutionContext):
context.log.info("World!")
Get started
Quickstart
Build your first Dagster pipeline in our Quickstart tutorial.
Thinking in Assets
New to Dagster? Learn about how thinking in assets can help you manage your data better.
Dagster Plus
Learn about Dagster Plus, our managed offering that includes a hosted Dagster instance and many more features.
Join the Dagster community
Slack
Join our Slack community to talk with other Dagster users, use our AI-powered chatbot, and get help with Dagster.
GitHub
Star our GitHub repository and follow our development through GitHub Discussions.
YouTube
Watch our latest videos on YouTube.
Dagster University
Learn Dagster through interactive courses and hands-on tutorials.