Partitioning assets
You can scaffold assets from the command line by running dg scaffold defs dagster.asset <path/to/asset_file.py>. For more information, see the dg CLI docs.
In Dagster, partitioning is a powerful technique for managing large datasets, improving pipeline performance, and enabling incremental processing. This guide will help you understand how to implement data partitioning in your Dagster projects.
There are several ways to partition your data in Dagster:
- Time-based partitioning, for processing data in specific time intervals
- Static partitioning, for dividing data based on predefined categories
- Two-dimensional partitioning, for partitioning data along two different axes simultaneously
- Dynamic partitioning, for creating partitions based on runtime information
We recommend limiting the number of partitions for each asset to 100,000 or fewer. Assets with partition counts exceeding this limit will likely have slower load times in the UI.
Time-based partitions
A common use case for partitioning is to process data that can be divided into time intervals, such as daily logs or monthly reports.
import datetime
import os
import pandas as pd
import dagster as dg
# Create the PartitionDefinition,
# which will create a range of partitions from
# 2024-01-01 to the day before the current time
daily_partitions = dg.DailyPartitionsDefinition(start_date="2024-01-01")
# Define the partitioned asset
@dg.asset(partitions_def=daily_partitions)
def daily_sales_data(context: dg.AssetExecutionContext) -> None:
date = context.partition_key
# Simulate fetching daily sales data
df = pd.DataFrame(
{
"date": [date] * 10,
"sales": [100, 200, 300, 400, 500, 600, 700, 800, 900, 1000],
}
)
os.makedirs("data/daily_sales", exist_ok=True)
filename = f"data/daily_sales/sales_{date}.csv"
df.to_csv(filename, index=False)
context.log.info(f"Daily sales data written to {filename}")
@dg.asset(
partitions_def=daily_partitions, # Use the daily partitioning scheme
deps=[daily_sales_data], # Define dependency on `daily_sales_data` asset
)
def daily_sales_summary(context):
partition_date_str = context.partition_key
# Read the CSV file for the given partition date
filename = f"data/daily_sales/sales_{partition_date_str}.csv"
df = pd.read_csv(filename)
# Summarize daily sales
summary = {
"date": partition_date_str,
"total_sales": df["sales"].sum(),
}
context.log.info(f"Daily sales summary for {partition_date_str}: {summary}")
# Create a partitioned asset job
daily_sales_job = dg.define_asset_job(
name="daily_sales_job",
selection=[daily_sales_data, daily_sales_summary],
)
# Create a schedule to run the job daily
@dg.schedule(
job=daily_sales_job,
cron_schedule="0 1 * * *", # Run at 1:00 AM every day
)
def daily_sales_schedule(context):
"""Process previous day's sales data."""
# Calculate the previous day's date
previous_day = context.scheduled_execution_time.date() - datetime.timedelta(days=1)
date = previous_day.strftime("%Y-%m-%d")
return dg.RunRequest(
run_key=date,
partition_key=date,
)
Partitions with predefined categories
Sometimes you have a set of predefined categories for your data. For instance, you might want to process data separately for different regions.
import os
import pandas as pd
import dagster as dg
# Create the PartitionDefinition
region_partitions = dg.StaticPartitionsDefinition(["us", "eu", "jp"])
# Define the partitioned asset
@dg.asset(partitions_def=region_partitions) # Use the region partitioning scheme
def regional_sales_data(context: dg.AssetExecutionContext) -> None:
region = context.partition_key
# Simulate fetching daily sales data
df = pd.DataFrame(
{
"region": [region] * 10,
"sales": [100, 200, 300, 400, 500, 600, 700, 800, 900, 1000],
}
)
os.makedirs("data/regional_sales", exist_ok=True)
filename = f"data/regional_sales/sales_{region}.csv"
df.to_csv(filename, index=False)
context.log.info(f"Regional sales data written to {filename}")
@dg.asset(
partitions_def=region_partitions, # Use the region partitioning scheme
deps=[regional_sales_data],
)
def daily_sales_summary(context):
region = context.partition_key
# Read the CSV file for the given partition date
filename = f"data/regional_sales/sales_{region}.csv"
df = pd.read_csv(filename)
# Summarize daily sales
summary = {
"region": region,
"total_sales": df["sales"].sum(),
}
context.log.info(f"Regional sales summary for {region}: {summary}")
# Create a partitioned asset job
regional_sales_job = dg.define_asset_job(
name="regional_sales_job",
selection=[regional_sales_data, daily_sales_summary],
)
Two-dimensional partitions
Two-dimensional partitioning allows you to partition data along two different axes simultaneously. This is useful when you need to process data that can be categorized in multiple ways. For example:
import datetime
import os
import pandas as pd
import dagster as dg
# Create two PartitionDefinitions
daily_partitions = dg.DailyPartitionsDefinition(start_date="2024-01-01")
region_partitions = dg.StaticPartitionsDefinition(["us", "eu", "jp"])
two_dimensional_partitions = dg.MultiPartitionsDefinition(
{"date": daily_partitions, "region": region_partitions}
)
# Define the partitioned asset
@dg.asset(partitions_def=two_dimensional_partitions)
def daily_regional_sales_data(context: dg.AssetExecutionContext) -> None:
# partition_key looks like "2024-01-01|us"
keys_by_dimension: dg.MultiPartitionKey = context.partition_key.keys_by_dimension
date = keys_by_dimension["date"] # ty: ignore[invalid-argument-type]
region = keys_by_dimension["region"] # ty: ignore[invalid-argument-type]
# Simulate fetching daily sales data
df = pd.DataFrame(
{
"date": [date] * 10,
"region": [region] * 10,
"sales": [100, 200, 300, 400, 500, 600, 700, 800, 900, 1000],
}
)
os.makedirs("data/daily_regional_sales", exist_ok=True)
filename = f"data/daily_regional_sales/sales_{context.partition_key}.csv"
df.to_csv(filename, index=False)
context.log.info(f"Daily sales data written to {filename}")
@dg.asset(
partitions_def=two_dimensional_partitions,
deps=[daily_regional_sales_data],
)
def daily_regional_sales_summary(context):
# partition_key looks like "2024-01-01|us"
keys_by_dimension: dg.MultiPartitionKey = context.partition_key.keys_by_dimension
date = keys_by_dimension["date"] # ty: ignore[invalid-argument-type]
region = keys_by_dimension["region"] # ty: ignore[invalid-argument-type]
filename = f"data/daily_regional_sales/sales_{context.partition_key}.csv"
df = pd.read_csv(filename)
# Summarize daily sales
summary = {
"date": date,
"region": region,
"total_sales": df["sales"].sum(),
}
context.log.info(f"Daily sales summary for {context.partition_key}: {summary}")
# Create a partitioned asset job
daily_regional_sales_job = dg.define_asset_job(
name="daily_regional_sales_job",
selection=[daily_regional_sales_data, daily_regional_sales_summary],
)
# Create a schedule to run the job daily
@dg.schedule(
job=daily_regional_sales_job,
cron_schedule="0 1 * * *", # Run at 1:00 AM every day
)
def daily_regional_sales_schedule(context):
"""Process previous day's sales data for all regions."""
previous_day = context.scheduled_execution_time.date() - datetime.timedelta(days=1)
date = previous_day.strftime("%Y-%m-%d")
# Create a run request for each region (3 runs in total every day)
return [
dg.RunRequest(
run_key=f"{date}|{region}",
partition_key=dg.MultiPartitionKey({"date": date, "region": region}),
)
for region in region_partitions.get_partition_keys()
]
In this example:
- Using
MultiPartitionsDefinition, thetwo_dimensional_partitionsis defined with two dimensions:dateandregion - The partition key would be:
2024-08-01|us - The
daily_regional_sales_dataanddaily_regional_sales_summaryassets are defined with the same two-dimensional partitioning scheme - The
daily_regional_sales_scheduleruns daily at 1:00 AM, processing the previous day's data for all regions. It usesMultiPartitionKeyto specify partition keys for both date and region dimensions, resulting in three runs per day, one for each region.
Partitions with dynamic categories
Sometimes you don't know the partitions in advance. For example, you might want to process new regions that are added in your system. In these cases, you can use dynamic partitioning to create partitions based on runtime information.
Consider this example:
import os
import pandas as pd
import dagster as dg
# Create the PartitionDefinition
region_partitions = dg.DynamicPartitionsDefinition(name="regions")
# Define the partitioned asset
@dg.asset(partitions_def=region_partitions)
def regional_sales_data(context: dg.AssetExecutionContext) -> None:
region = context.partition_key
# Simulate fetching daily sales data
df = pd.DataFrame(
{
"region": [region] * 10,
"sales": [100, 200, 300, 400, 500, 600, 700, 800, 900, 1000],
}
)
os.makedirs("data/regional_sales", exist_ok=True)
filename = f"data/regional_sales/sales_{region}.csv"
df.to_csv(filename, index=False)
context.log.info(f"Regional sales data written to {filename}")
@dg.asset(
partitions_def=region_partitions,
deps=[regional_sales_data],
)
def daily_sales_summary(context):
region = context.partition_key
# Read the CSV file for the given partition date
filename = f"data/regional_sales/sales_{region}.csv"
df = pd.read_csv(filename)
# Summarize daily sales
summary = {
"region": region,
"total_sales": df["sales"].sum(),
}
context.log.info(f"Regional sales summary for {region}: {summary}")
# Create a partitioned asset job
regional_sales_job = dg.define_asset_job(
name="regional_sales_job",
selection=[regional_sales_data, daily_sales_summary],
)
@dg.sensor(job=regional_sales_job)
def all_regions_sensor(context: dg.SensorEvaluationContext):
# Simulate fetching all regions from an external system
all_regions = ["us", "eu", "jp", "ca", "uk", "au"]
return dg.SensorResult(
run_requests=[dg.RunRequest(partition_key=region) for region in all_regions],
dynamic_partitions_requests=[region_partitions.build_add_request(all_regions)],
)
In this example:
- Because the partition values are unknown in advance,
DynamicPartitionsDefinitionis used to defineregion_partitions - When triggered, the
all_regions_sensorwill dynamically add all regions to the partition set. Once it kicks off runs, it will dynamically kick off runs for all regions. In this example, that would be six times; one for each region.
Partitions with custom calendars
Sometimes you want to partition an asset or create a schedule for a partition that is more complex or involves a custom calendar. In these cases, you can include additional logic besides cron syntax.
In this example:
- The holidays are defined
- The
TimeWindowPartitionsDefinitioncreates a partition using thecron_schedule, but excludes the defined holidays - The
market_dataasset is partition by the cron schedule (every Monday through Friday), except for the holidays listed
from datetime import datetime
import dagster as dg
# Define your market holidays
market_holidays_2024_strings = [
"2024-01-01", # New Year's Day
"2024-01-15", # Martin Luther King Jr. Day
"2024-02-19", # Presidents Day
"2024-03-29", # Good Friday
"2024-05-27", # Memorial Day
"2024-06-19", # Juneteenth
"2024-07-04", # Independence Day
"2024-09-02", # Labor Day
"2024-11-28", # Thanksgiving
"2024-12-25", # Christmas Day
]
exclusions = [
datetime.strptime(date_str, "%Y-%m-%d") for date_str in market_holidays_2024_strings
]
# Create weekday partitions excluding holidays
market_calendar = dg.TimeWindowPartitionsDefinition(
start=datetime(2024, 1, 1),
cron_schedule="0 0 * * 1-5", # Weekdays only
fmt="%Y-%m-%d",
# Exclude specific holiday dates
exclusions=exclusions,
)
@dg.asset(partitions_def=market_calendar)
def market_data(context: dg.AssetExecutionContext):
trading_date = context.partition_key
context.log.info(f"Processing market data for trading day: {trading_date}")
Materializing partitioned assets
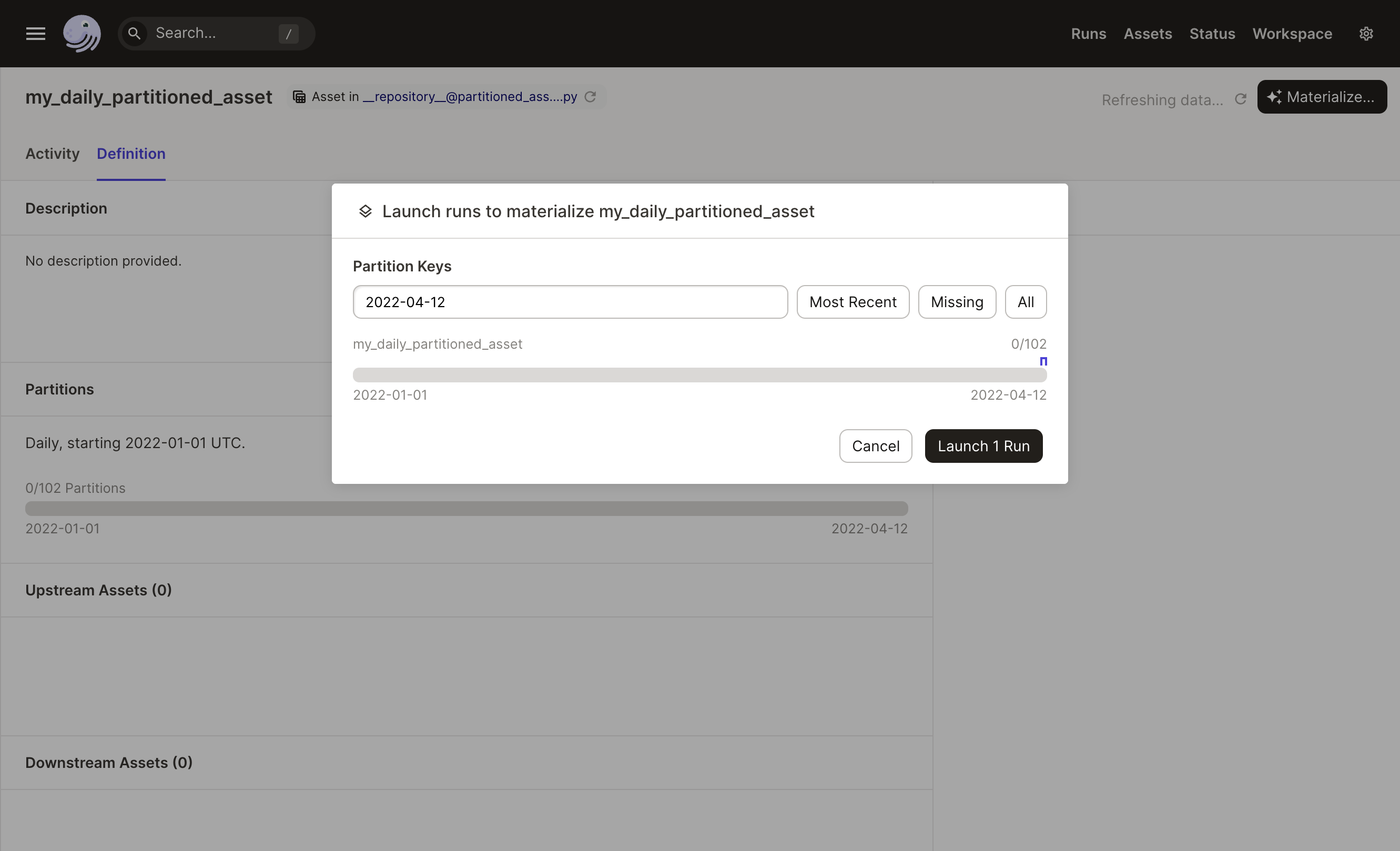
When you materialize a partitioned asset, you choose which partitions to materialize and Dagster will launch a run for each partition.
If you choose more than one partition, the Dagster daemon needs to be running to queue the multiple runs.
The following image shows the Launch runs dialog on an asset's Details page, where you'll be prompted to select a partition to materialize:
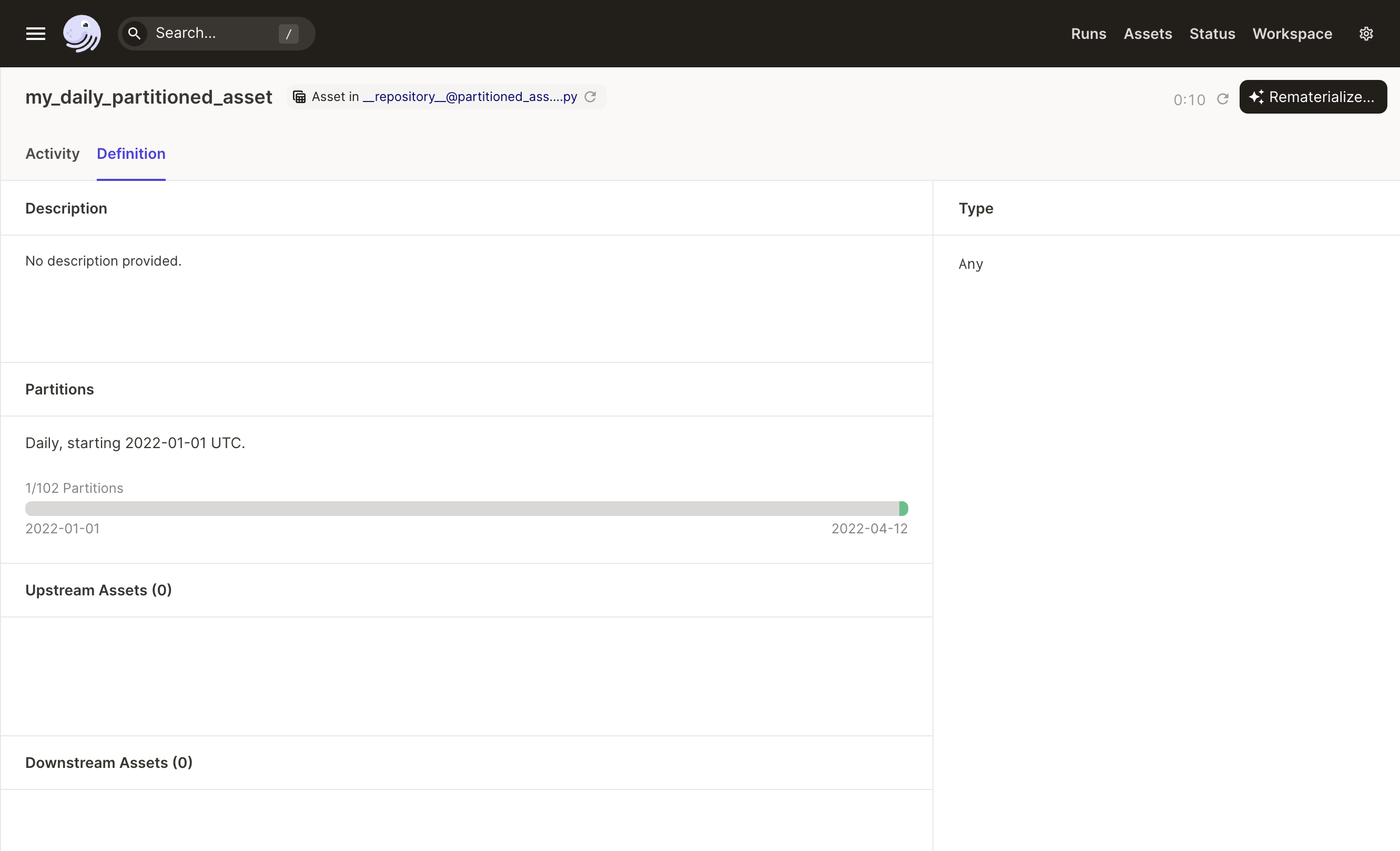
After a partition has been successfully materialized, it will display as green in the partitions bar:
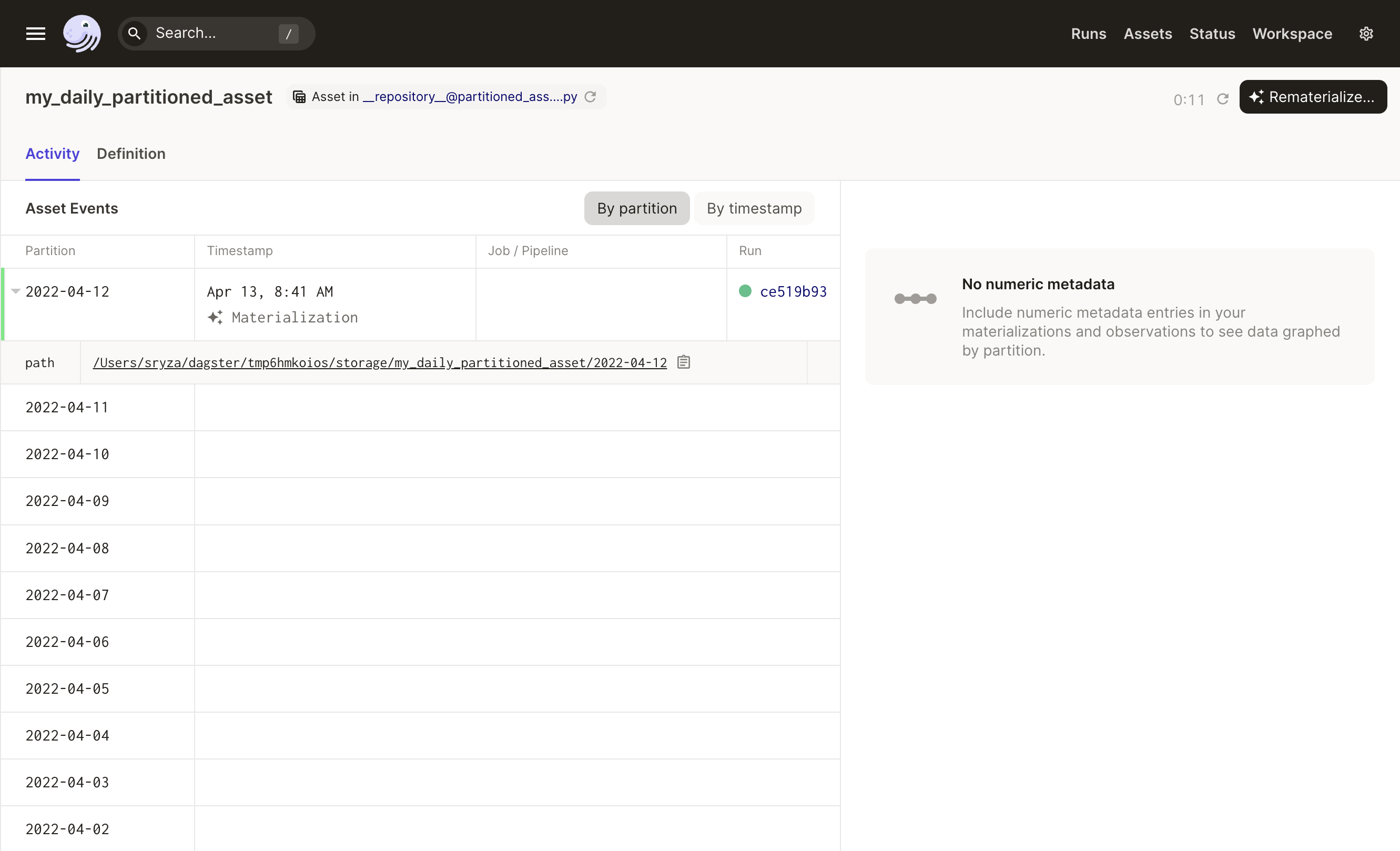
Viewing materializations by partition
To view materializations by partition for a specific asset, navigate to the Activity tab of the asset's Details page: