Dagster & Pandera
This feature is considered in a beta stage. It is still being tested and may change. For more information, see the API lifecycle stages documentation.
The Pandera integration library provides an API for generating Dagster Types from Pandera dataframe schemas. Like all Dagster types, Pandera-generated types can be used to annotate op inputs and outputs.
Using Pandera with Dagster allows you to:
- Visualize the shape of the data by displaying dataframe structure information in the Dagster UI
- Implement runtime type-checking with rich error reporting
Limitations
Currently, dagster-pandera only supports pandas and Polars dataframes, despite Pandera supporting validation on other dataframe backends.
Prerequisites
To get started, you'll need:
-
To install the
dagsteranddagster-panderaPython packages:- uv
- pip
uv add dagster-panderapip install dagster-pandera -
Familiarity with [Dagster Types](/api/dagster/types
Usage
The dagster-pandera library exposes only a single public function, pandera_schema_to_dagster_type, which generates Dagster types from Pandera schemas. The Dagster type wraps the Pandera schema and invokes the schema's validate() method inside its type check function.
import random
import pandas as pd
import pandera as pa
from dagster_pandera import pandera_schema_to_dagster_type
from pandera.typing import Series
from dagster import Out, job, op
APPLE_STOCK_PRICES = {
"name": ["AAPL", "AAPL", "AAPL", "AAPL", "AAPL"],
"date": ["2018-01-22", "2018-01-23", "2018-01-24", "2018-01-25", "2018-01-26"],
"open": [177.3, 177.3, 177.25, 174.50, 172.0],
"close": [177.0, 177.04, 174.22, 171.11, 171.51],
}
class StockPrices(pa.DataFrameModel):
"""Open/close prices for one or more stocks by day."""
name: Series[str] = pa.Field(description="Ticker symbol of stock")
date: Series[str] = pa.Field(description="Date of prices")
open: Series[float] = pa.Field(ge=0, description="Price at market open")
close: Series[float] = pa.Field(ge=0, description="Price at market close")
@op(out=Out(dagster_type=pandera_schema_to_dagster_type(StockPrices)))
def apple_stock_prices_dirty():
prices = pd.DataFrame(APPLE_STOCK_PRICES)
i = random.choice(prices.index)
prices.loc[i, "open"] = pd.NA
prices.loc[i, "close"] = pd.NA
return prices
@job
def stocks_job():
apple_stock_prices_dirty()
In the above example, we defined a toy job (stocks_job) with a single asset, apple_stock_prices_dirty. This asset returns a pandas DataFrame containing the opening and closing prices of Apple stock (AAPL) for a random week. The _dirty suffix is included because we've corrupted the data with a few random nulls.
Let's look at this job in the UI:
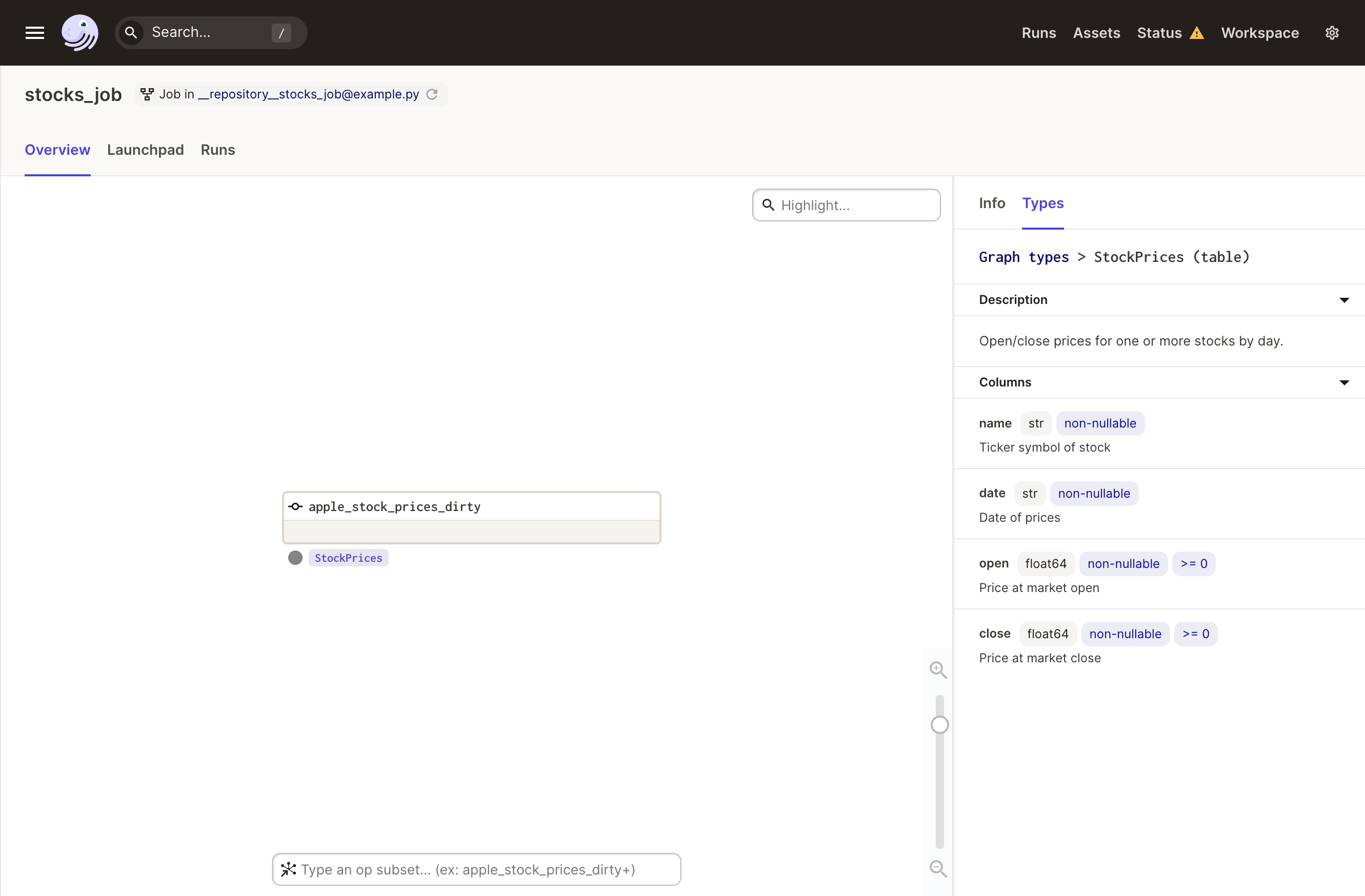
Notice that information from the StockPrices Pandera schema is rendered in the asset detail area of the right sidebar. This is possible because pandera_schema_to_dagster_type extracts this information from the Pandera schema and attaches it to the returned Dagster type.
If we try to run stocks_job, our run will fail. This is expected, as our (dirty) data contains nulls and Pandera columns are non-nullable by default. The Dagster Typ returned by pandera_schema_to_dagster_type contains a type check function that calls StockPrices.validate(). This is invoked automatically on the return value of apple_stock_prices_dirty, leading to a type check failure.
Notice the STEP_OUTPUT event in the following screenshot to see Pandera's full output:
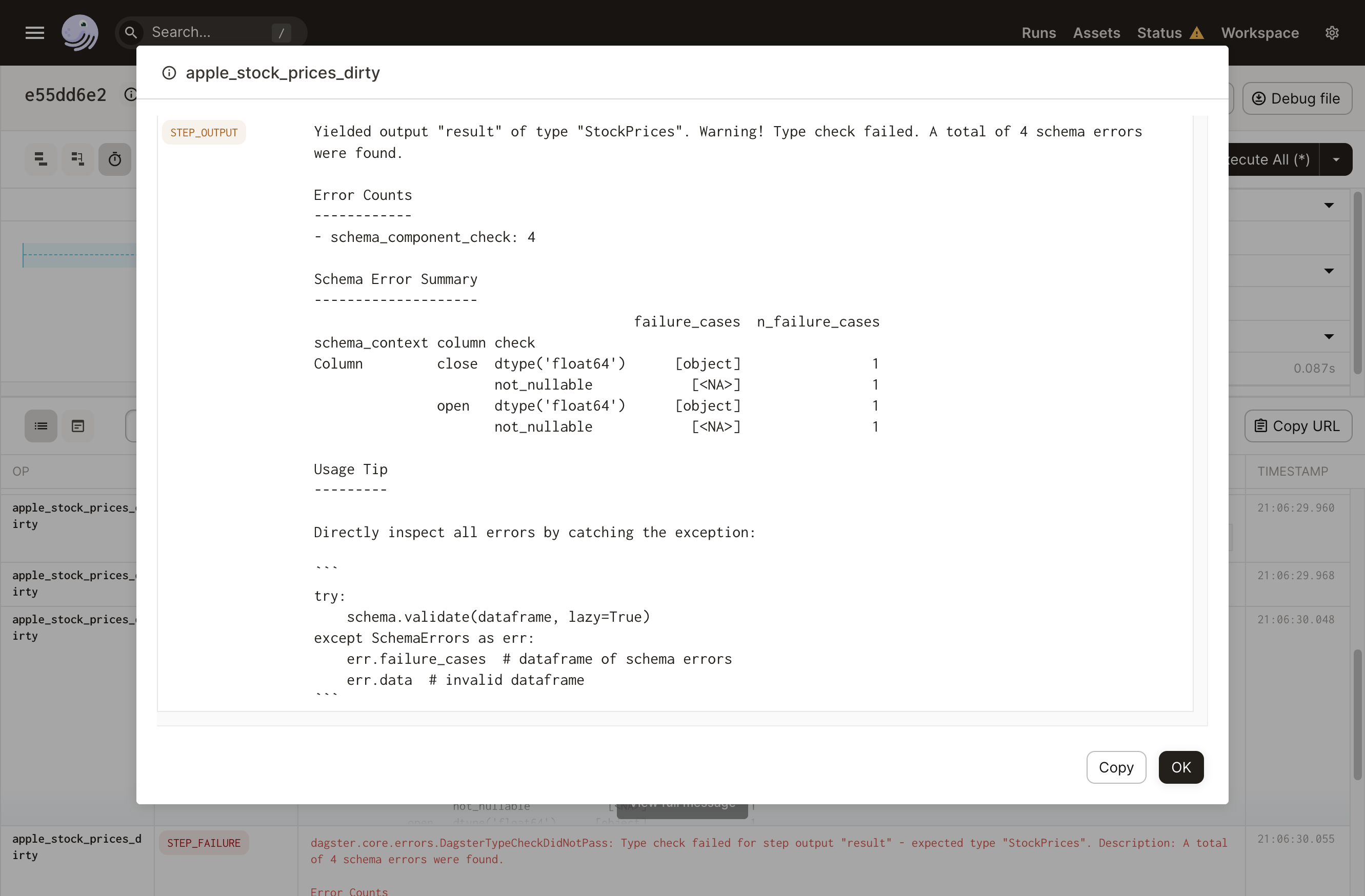
About Pandera
Pandera is a statistical data testing toolkit, and a data validation library for scientists, engineers, and analysts seeking correctness.