dagster-dbt integration reference
Using dbt Cloud? See Dagster & dbt Cloud.
This reference provides a high-level look at working with dbt models through Dagster's software-defined assets framework using the dagster-dbt integration library.
For a step-by-step implementation walkthrough, see Dagster & dbt.
Relevant APIs
| Name | Description |
|---|---|
dagster-dbt project scaffold | A CLI command to initialize a new Dagster project for an existing dbt project. |
@dagster_dbt.dbt_assets | A decorator used to define Dagster assets for dbt models defined in a dbt manifest. |
DbtCliResource | A class that defines a Dagster resource used to execute dbt CLI commands. |
DbtCliInvocation | A class that defines the representation of an invoked dbt command. |
DbtProject | A class that defines the representation of a dbt project and related settings that assist with managing dependencies and manifest.json preparation. |
DagsterDbtTranslator | A class that can be overridden to customize how Dagster asset metadata is derived from a dbt manifest. |
DagsterDbtTranslatorSettings | A class with settings to enable Dagster features for a dbt project. |
DbtManifestAssetSelection | A class that defines a selection of assets from a dbt manifest and a dbt selection string. |
build_dbt_asset_selection | A helper method that builds a DbtManifestAssetSelection from a dbt manifest and dbt selection string. |
build_schedule_from_dbt_selection | A helper method that builds a ScheduleDefinition from a dbt manifest, dbt selection string, and cron string. |
get_asset_key_for_model | A helper method that retrieves the AssetKey for a dbt model. |
get_asset_key_for_source | A helper method that retrieves the AssetKey for a dbt source with a singular table. |
get_asset_keys_by_output_name_for_source | A helper method that retrieves the AssetKeys for a dbt source with multiple tables. |
dbt models and Dagster asset definitions
Dagster’s asset definitions bear several similarities to dbt models. An asset definition contains an asset key, a set of upstream asset keys, and an operation that is responsible for computing the asset from its upstream dependencies. Models defined in a dbt project can be interpreted as Dagster asset definitions:
- The asset key for a dbt model is (by default) the name of the model.
- The upstream dependencies of a dbt model are defined with
reforsourcecalls within the model's definition. - The computation required to compute the asset from its upstream dependencies is the SQL within the model's definition.
These similarities make it natural to interact with dbt models as asset definitions. Let’s take a look at a dbt model and an asset definition, in code:
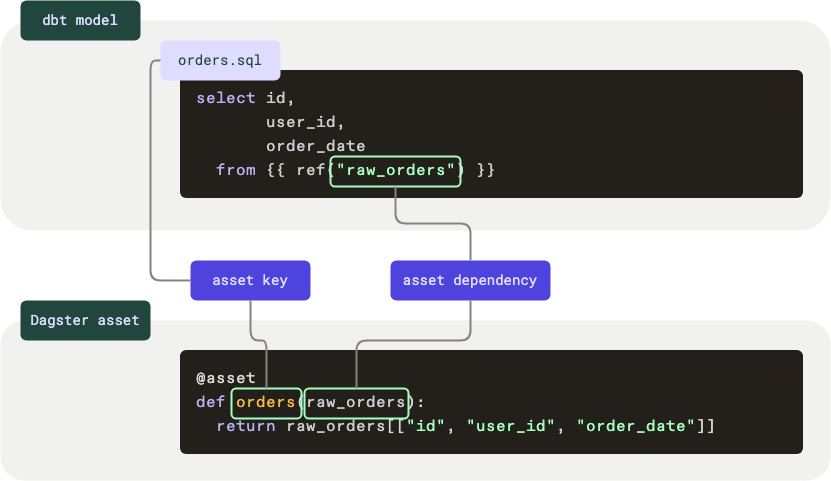
Here's what's happening in this example:
- The first code block is a dbt model
- As dbt models are named using file names, this model is named
orders - The data for this model comes from a dependency named
raw_orders
- As dbt models are named using file names, this model is named
- The second code block is a Dagster asset
- The asset key corresponds to the name of the dbt model,
orders raw_ordersis provided as an argument to the asset, defining it as a dependency
- The asset key corresponds to the name of the dbt model,
Scaffolding a Dagster project from a dbt project
You can create a Dagster project that wraps your dbt project by using the dagster-dbt project scaffold command line interface.
dagster-dbt project scaffold --project-name project_dagster --dbt-project-dir path/to/dbt/project
This creates a directory called project_dagster/ inside the current directory. The project_dagster/ directory contains a set of files that define a Dagster project that loads the dbt project at the path defined by --dbt-project-dir. The path to the dbt project must contain a dbt_project.yml.
Loading dbt models from a dbt project
The dagster-dbt library offers @dagster_dbt.dbt_assets to define Dagster assets for dbt models. It requires a dbt manifest, or manifest.json, to be created from your dbt project to parse your dbt project's representation.
The manifest can be created in two ways:
- At run time: A dbt manifest is generated when your Dagster definitions are loaded, or
- At build time: A dbt manifest is generated before loading your Dagster definitions and is included as part of your Python package.
When deploying your Dagster project to production, we recommend generating the manifest at build time to avoid the overhead of recompiling your dbt project every time your Dagster code is executed. A manifest.json should be precompiled and included in the Python package for your Dagster code.
The easiest way to handle the creation of your manifest file is to use DbtProject.
In the Dagster project created by the dagster-dbt project scaffold command, the creation of your manifest is handled at run time during development:
from pathlib import Path
from dagster_dbt import DbtProject
my_dbt_project = DbtProject(
project_dir=Path(__file__).joinpath("..", "..", "..").resolve(),
packaged_project_dir=Path(__file__)
.joinpath("..", "..", "dbt-project")
.resolve(),
)
my_dbt_project.prepare_if_dev()
The manifest path can then be accessed with my_dbt_project.manifest_path.
When developing locally, you can run the following command to generate the manifest at run time for your dbt and Dagster project:
dagster dev
In production, a precompiled manifest should be used. Using DbtProject, the manifest can be created at build time by running the dagster-dbt project prepare-and-package command in your CI/CD workflow. For more information, see the Deploying a Dagster project with a dbt project section.
Customizing the manifest generation command
By default, DbtProject runs dbt parse --quiet to generate the manifest. You can customize this by passing prepare_project_cli_args to DbtProject. For example, to use dbt compile (which populates compiled_code on each node in the manifest):
from pathlib import Path
from dagster_dbt import DbtProject
my_dbt_project = DbtProject(
project_dir=Path("path/to/dbt_project"),
prepare_project_cli_args=["compile", "--quiet"],
)
This is useful when you need access to compiled SQL in asset metadata, descriptions, or custom translators.
Selecting a profiles directory, profile and target for your dbt project
You can specify which connection information dbt should use when parsing and executing your models. This can be done by passing the profiles directory, profile and target when creating your DbtProject object. These fields are optional - the default values defined in your dbt project will be used for each parameter that is not passed.
from pathlib import Path
from dagster_dbt import DbtProject
my_dbt_project = DbtProject(
project_dir=Path(__file__).joinpath("..", "..", "..").resolve(),
profiles_dir=Path(__file__)
.joinpath("..", "..", "..", "my_profiles_dir")
.resolve(),
profile="my_profile",
target="my_target",
)
For more information, see dbt's guide about connection profiles.
Deploying a Dagster project with a dbt project
Got questions about our recommendations or something to add?
Join our GitHub discussion to share how you deploy your Dagster code with your dbt project.
When deploying your Dagster project to production, your dbt project must be present alongside your Dagster project so that dbt commands can be executed. As a result, we recommend that you set up your continuous integration and continuous deployment (CI/CD) workflows to package the dbt project with your Dagster project.
Deploying a dbt project from a separate git repository
If you are managing your Dagster project in a separate git repository from your dbt project, you should include the following steps in your CI/CD workflows.
In your CI/CD workflows for your Dagster project:
- Include any secrets that are required by your dbt project in your CI/CD environment.
- Clone the dbt project repository as a subdirectory of your Dagster project.
- Run
dagster-dbt project prepare-and-package --file path/to/project.pyto- Build your dbt project's dependencies,
- Create a dbt manifest for your Dagster project, and
- Package your dbt project
If you are using Components, you can prepare your DbtProjectComponent using dagster-dbt project prepare-and-package --components path/to/project-root
In the CI/CD workflows for your dbt project, set up a dispatch action to trigger a deployment of your Dagster project when your dbt project changes.
Deploying a dbt project from a monorepo
With Dagster+, we streamline this option. As part of our Dagster+ onboarding for dbt users, we can automatically create a Dagster project in an existing dbt project repository.
If you are managing your Dagster project in the same git repository as your dbt project, you should include the following steps in your CI/CD workflows.
In your CI/CD workflows for your Dagster and dbt project:
- Include any secrets that are required by your dbt project in your CI/CD environment.
- Run
dagster-dbt project prepare-and-package --file path/to/project.pyto- Build your dbt project's dependencies,
- Create a dbt manifest for your Dagster project, and
- Package your dbt project
If you are using Components, you can prepare your DbtProjectComponent using dagster-dbt project prepare-and-package --components path/to/project-root
Leveraging dbt defer with branch deployments
This feature requires the DAGSTER_BUILD_STATEDIR environment variable to be set in your CI/CD. Learn more about required environment variables in CI/CD for Dagster+ here.
You will also need to run the dagster-cloud ci dagster-dbt project manage-state command in your prod deployment before it can be run in branch deployments. This will create the baseline for comparison in the branch deployments.
It is possible to leverage dbt defer by passing a state_path to DbtProject. This is useful for testing recent changes made in development against the state of the dbt project in production. Using dbt defer, you can run a subset of models or tests, those that have been changed between development and production, without having to build their upstream parents first.
In practice, this is most useful when combined with branch deployments in Dagster+, to test changes made in your branches. This can be done by updating your CI/CD files and your Dagster code.
First, let's take a look at your CI/CD files. You might have one or two CI/CD files to manage your production and branch deployments. In these files, find the steps related to your dbt project. For more information, see the section on deploying a Dagster project with a dbt project.
Once your dbt steps are located, add the following step to manage the state of your dbt project.
dagster-cloud ci dagster-dbt project manage-state --file path/to/project.py
The dagster-cloud ci dagster-dbt project manage-state CLI command fetches the manifest.json file from your production branch and saves it to a state directory, in order to power the dbt defer command.
In practice, this command fetches the manifest.json file from your production branch and add it to the state directory set to the state_path of the DbtProject found in path/to/project.py. The production manifest.json file can then be used as the deferred dbt artifacts.
Now that your CI/CD files are updated to manage the state of your dbt project using the dagster-cloud CLI, we need to update the Dagster code to pass a state directory to the DbtProject.
Update your Dagster code to pass a state_path to your DbtProject object. Note that value passed to state_path must be a path, relative to the dbt project directory, to a state directory of dbt artifacts. In the code below, we set the state_path to 'state/'. If this directory does not exist in your project structure, it will be created by Dagster.
Also, update the dbt command in your @dbt_assets definition to pass the defer args using get_defer_args.
from pathlib import Path
from dagster import AssetExecutionContext
from dagster_dbt import DbtCliResource, DbtProject, dbt_assets
my_dbt_project = DbtProject(
project_dir=Path(__file__).joinpath("..", "..", "..").resolve(),
packaged_project_dir=Path(__file__)
.joinpath("..", "..", "dbt-project")
.resolve(),
state_path=Path("state"),
)
my_dbt_project.prepare_if_dev()
@dbt_assets(manifest=my_dbt_project.manifest_path)
def my_dbt_assets(
context: AssetExecutionContext,
dbt: DbtCliResource,
):
yield from dbt.cli(["build", *dbt.get_defer_args()], context=context).stream()
Using config with @dbt_assets
Similar to Dagster software-defined assets, @dbt_assets can use a config system to enable run configuration. This allows to provide parameters to jobs at the time they're executed.
In the context of dbt, this can be useful if you want to run commands or flags for specific use cases. For instance, you may want to add the --full-refresh flag to your dbt commands in some cases. Using a config system, the @dbt_assets object can be easily modified to support this use case.
from pathlib import Path
from dagster import AssetExecutionContext, Config
from dagster_dbt import DbtCliResource, DbtProject, dbt_assets
my_dbt_project = DbtProject(project_dir=Path("path/to/dbt_project"))
class MyDbtConfig(Config):
full_refresh: bool
@dbt_assets(manifest=my_dbt_project.manifest_path)
def my_dbt_assets(
context: AssetExecutionContext, dbt: DbtCliResource, config: MyDbtConfig
):
dbt_build_args = ["build"]
if config.full_refresh:
dbt_build_args += ["--full-refresh"]
yield from dbt.cli(dbt_build_args, context=context).stream()
Now that the @dbt_assets object is updated, the run configuration can be passed to a job.
from dagster import RunConfig, define_asset_job
from dagster_dbt import build_dbt_asset_selection
my_job = define_asset_job(
name="all_dbt_assets",
selection=build_dbt_asset_selection(
[my_dbt_assets],
),
config=RunConfig(
ops={"my_dbt_assets": MyDbtConfig(full_refresh=True, seed=True)}
),
)
In the example above, the job is configured to use the --full-refresh flag with the dbt build command when materializing the assets.
Scheduling dbt jobs
Once you have your dbt assets, you can define a job to materialize a selection of these assets on a schedule.
Scheduling jobs that contain only dbt assets
In this example, we use the build_schedule_from_dbt_selection function to create a job, daily_dbt_models, as well as a schedule which will execute this job once a day. We define the set of models we'd like to execute using dbt's selection syntax, in this case selecting only the models with the tag daily.
from dagster_dbt import build_schedule_from_dbt_selection, dbt_assets
@dbt_assets(manifest=manifest)
def my_dbt_assets(): ...
daily_dbt_assets_schedule = build_schedule_from_dbt_selection(
[my_dbt_assets],
job_name="daily_dbt_models",
cron_schedule="@daily",
dbt_select="tag:daily",
# If your definition of `@dbt_assets` has Dagster Configuration, you can specify it here.
# config=RunConfig(ops={"my_dbt_assets": MyDbtConfig(full_refresh=True)}),
)
Scheduling jobs that contain dbt assets and non-dbt assets
In many cases, it's useful to be able to schedule dbt assets alongside non-dbt assets. In this example, we build an AssetSelection of dbt assets using build_dbt_asset_selection, then select all assets (dbt-related or not) which are downstream of these dbt models. From there, we create a job that targets that selection of assets and schedule it to run daily.
from dagster import define_asset_job, ScheduleDefinition
from dagster_dbt import build_dbt_asset_selection, dbt_assets
@dbt_assets(manifest=manifest)
def my_dbt_assets(): ...
# selects all models tagged with "daily", and all their downstream asset dependencies
daily_selection = build_dbt_asset_selection(
[my_dbt_assets], dbt_select="tag:daily"
).downstream()
daily_dbt_assets_and_downstream_schedule = ScheduleDefinition(
job=define_asset_job("daily_assets", selection=daily_selection),
cron_schedule="@daily",
)
Refer to the Schedule documentation for more info on running jobs on a schedule.
Understanding asset definition attributes
In Dagster, each asset definition has attributes. Dagster automatically generates these attributes for each asset definition loaded from the dbt project. These attributes can optionally be overridden by the user.
- Customizing asset keys
- Customizing group names
- Customizing owners
- Customizing descriptions
- Customizing metadata
- Customizing tags
- Customizing automation conditions
Customizing asset keys
For dbt models, seeds, and snapshots, the default asset key will be the configured schema for that node, concatenated with the name of the node.
| dbt node type | Schema | Model name | Resulting asset key |
|---|---|---|---|
| model, seed, snapshot | None | MODEL_NAME | MODEL_NAME |
SCHEMA | MODEL_NAME | SCHEMA/MODEL_NAME | |
None | my_model | some_model | |
| marketing | my_model | marketing/my_model |
For dbt sources, the default asset key will be the name of the source concatenated with the name of the source table.
| dbt node type | Source name | Table name | Resulting asset key |
|---|---|---|---|
| source | SOURCE_NAME | TABLE_NAME | SOURCE_NAME/TABLE_NAME |
| jaffle_shop | orders | jaffle_shop/orders |
There are two ways to customize the asset keys generated by Dagster for dbt assets:
- Defining meta config on your dbt node, or
- Overriding Dagster's asset key generation by implementing a custom
DagsterDbtTranslator.
To override an asset key generated by Dagster for a dbt node, you can define a meta key on your dbt node's .yml file. The following example overrides the asset key for a source and table as snowflake/jaffle_shop/orders:
sources:
- name: jaffle_shop
tables:
- name: orders
meta:
dagster:
asset_key: ['snowflake', 'jaffle_shop', 'orders']
Alternatively, to override the asset key generation for all dbt nodes in your dbt project, you can create a custom DagsterDbtTranslator and implement DagsterDbtTranslator.get_asset_key. The following example adds a snowflake prefix to the default generated asset key:
from pathlib import Path
from dagster import AssetKey, AssetExecutionContext
from dagster_dbt import DagsterDbtTranslator, DbtCliResource, DbtProject, dbt_assets
from typing import Any
from collections.abc import Mapping
my_dbt_project = DbtProject(project_dir=Path("path/to/dbt_project"))
class CustomDagsterDbtTranslator(DagsterDbtTranslator):
def get_asset_key(self, dbt_resource_props: Mapping[str, Any]) -> AssetKey:
return super().get_asset_key(dbt_resource_props).with_prefix("snowflake")
@dbt_assets(
manifest=my_dbt_project.manifest_path,
dagster_dbt_translator=CustomDagsterDbtTranslator(),
)
def my_dbt_assets(context: AssetExecutionContext, dbt: DbtCliResource):
yield from dbt.cli(["build"], context=context).stream()
Customizing group names
For dbt models, seeds, and snapshots, the default Dagster group name will be the dbt group defined for that node.
| dbt node type | dbt group name | Resulting Dagster group name |
|---|---|---|
| model, seed, snapshot | GROUP_NAME | GROUP_NAME |
None | None | |
| finance | finance |
There are three ways to customize the group names generated by Dagster for dbt assets:
- Defining meta config on your dbt node, or
- Overriding Dagster's group name generation by implementing a custom
DagsterDbtTranslator - Overriding Dagster's group name generation using
map_asset_specs
To override the group name generated by Dagster for a dbt node, you can define a meta key in your dbt project file, on your dbt node's property file, or on the node's in-file config block. The following example overrides the Dagster group name for the following model as marketing:
models:
- name: customers
config:
meta:
dagster:
group: marketing
Alternatively, to override the Dagster group name generation for all dbt nodes in your dbt project, you can create a custom DagsterDbtTranslator and implement DagsterDbtTranslator.get_group_name. The following example defines snowflake as the group name for all dbt nodes:
from pathlib import Path
from dagster import AssetExecutionContext
from dagster_dbt import DagsterDbtTranslator, DbtCliResource, DbtProject, dbt_assets
from typing import Any
from collections.abc import Mapping
my_dbt_project = DbtProject(project_dir=Path("path/to/dbt_project"))
class CustomDagsterDbtTranslator(DagsterDbtTranslator):
def get_group_name(self, dbt_resource_props: Mapping[str, Any]) -> str | None:
return "snowflake"
@dbt_assets(
manifest=my_dbt_project.manifest_path,
dagster_dbt_translator=CustomDagsterDbtTranslator(),
)
def my_dbt_assets(context: AssetExecutionContext, dbt: DbtCliResource):
yield from dbt.cli(["build"], context=context).stream()
Similarly, to override the Dagster group name generation for all dbt nodes in your dbt project, you can also use map_asset_specs. The following example defines snowflake as the group name for all dbt nodes:
from pathlib import Path
from dagster import AssetExecutionContext
from dagster_dbt import DbtCliResource, DbtProject, dbt_assets
my_dbt_project = DbtProject(project_dir=Path("path/to/dbt_project"))
@dbt_assets(
manifest=my_dbt_project.manifest_path,
)
def my_dbt_assets(context: AssetExecutionContext, dbt: DbtCliResource):
yield from dbt.cli(["build"], context=context).stream()
my_dbt_assets = my_dbt_assets.map_asset_specs(
lambda spec: spec.replace_attributes(group_name="snowflake")
)
Customizing owners
For dbt models, seeds, and snapshots, the default Dagster owner will be the email associated with the dbt group defined for that node.
| dbt node type | dbt group name | dbt group's email | Resulting Dagster owner |
|---|---|---|---|
| model, seed, snapshot | GROUP_NAME | OWNER@DOMAIN.COM | OWNER@DOMAIN.COM |
GROUP_NAME | None | None | |
None | None | None | |
| finance | owner@company.com | owner@company.com | |
| finance | None | None |
There are three ways to customize the owners generated by Dagster for dbt assets:
- Defining meta config on your dbt node, or
- Overriding Dagster's generation of owners by implementing a custom
DagsterDbtTranslator - Overriding Dagster's owners generation using
map_asset_specs
To override the owners generated by Dagster for a dbt node, you can define a meta key in your dbt project file, on your dbt node's property file, or on the node's in-file config block. The following example overrides the Dagster owners for the following model as owner@company.com and team:data@company.com:
models:
- name: customers
config:
meta:
dagster:
owners: ['owner@company.com', 'team:data@company.com']
Alternatively, to override the Dagster generation of owners for all dbt nodes in your dbt project, you can create a custom DagsterDbtTranslator and implement DagsterDbtTranslator.get_group_name. The following example defines owner@company.com and team:data@company.com as the owners for all dbt nodes:
from pathlib import Path
from dagster import AssetExecutionContext
from dagster_dbt import DagsterDbtTranslator, DbtCliResource, DbtProject, dbt_assets
from typing import Any
from collections.abc import Mapping, Sequence
my_dbt_project = DbtProject(project_dir=Path("path/to/dbt_project"))
class CustomDagsterDbtTranslator(DagsterDbtTranslator):
def get_owners(
self, dbt_resource_props: Mapping[str, Any]
) -> Sequence[str] | None:
return ["owner@company.com", "team:data@company.com"]
@dbt_assets(
manifest=my_dbt_project.manifest_path,
dagster_dbt_translator=CustomDagsterDbtTranslator(),
)
def my_dbt_assets(context: AssetExecutionContext, dbt: DbtCliResource):
yield from dbt.cli(["build"], context=context).stream()
Similarly, to override the Dagster owners generation for all dbt nodes in your dbt project, you can also use map_asset_specs. The following example defines owner@company.com and team:data@company.com as the owners for all dbt nodes:
from pathlib import Path
from dagster import AssetExecutionContext
from dagster_dbt import DbtCliResource, DbtProject, dbt_assets
my_dbt_project = DbtProject(project_dir=Path("path/to/dbt_project"))
@dbt_assets(
manifest=my_dbt_project.manifest_path,
)
def my_dbt_assets(context: AssetExecutionContext, dbt: DbtCliResource):
yield from dbt.cli(["build"], context=context).stream()
my_dbt_assets = my_dbt_assets.map_asset_specs(
lambda spec: spec.replace_attributes(
owners=["owner@company.com", "team:data@company.com"]
)
)
Customizing descriptions
For dbt models, seeds, and snapshots, the default Dagster description will be the dbt node's description.
To override the Dagster description for all dbt nodes in your dbt project, you can create a custom DagsterDbtTranslator and implement DagsterDbtTranslator.get_description. The following example defines the raw SQL of the dbt node as the Dagster description:
import textwrap
from pathlib import Path
from dagster import AssetExecutionContext
from dagster_dbt import DagsterDbtTranslator, DbtCliResource, DbtProject, dbt_assets
from typing import Any
from collections.abc import Mapping
my_dbt_project = DbtProject(project_dir=Path("path/to/dbt_project"))
class CustomDagsterDbtTranslator(DagsterDbtTranslator):
def get_description(self, dbt_resource_props: Mapping[str, Any]) -> str:
return textwrap.indent(dbt_resource_props.get("raw_sql", ""), "\t")
@dbt_assets(
manifest=my_dbt_project.manifest_path,
dagster_dbt_translator=CustomDagsterDbtTranslator(),
)
def my_dbt_assets(context: AssetExecutionContext, dbt: DbtCliResource):
yield from dbt.cli(["build"], context=context).stream()
Customizing metadata
For dbt models, seeds, and snapshots, the default Dagster definition metadata will be the dbt node's declared column schema.
To override the Dagster definition metadata for all dbt nodes in your dbt project, you can create a custom DagsterDbtTranslator and implement DagsterDbtTranslator.get_metadata. The following example defines the metadata of the dbt node as the Dagster metadata, using MetadataValue:
from pathlib import Path
from dagster import MetadataValue, AssetExecutionContext
from dagster_dbt import DagsterDbtTranslator, DbtCliResource, DbtProject, dbt_assets
from typing import Any
from collections.abc import Mapping
my_dbt_project = DbtProject(project_dir=Path("path/to/dbt_project"))
class CustomDagsterDbtTranslator(DagsterDbtTranslator):
def get_metadata(
self, dbt_resource_props: Mapping[str, Any]
) -> Mapping[str, Any]:
return {
"dbt_metadata": MetadataValue.json(dbt_resource_props.get("meta", {}))
}
@dbt_assets(
manifest=my_dbt_project.manifest_path,
dagster_dbt_translator=CustomDagsterDbtTranslator(),
)
def my_dbt_assets(context: AssetExecutionContext, dbt: DbtCliResource):
yield from dbt.cli(["build"], context=context).stream()
Dagster also supports fetching additional metadata at dbt execution time to attach to asset materializations. For more information, see the Customizing asset materialization metadata section.
Attaching code reference metadata
Dagster's dbt integration can automatically attach code reference metadata to the SQL files backing your dbt assets. To enable this feature, set the enable_code_references parameter to True in the DagsterDbtTranslatorSettings passed to your DagsterDbtTranslator:
from pathlib import Path
from dagster_dbt import (
DagsterDbtTranslator,
DagsterDbtTranslatorSettings,
DbtCliResource,
DbtProject,
dbt_assets,
)
from dagster import AssetExecutionContext, Definitions, with_source_code_references
my_project = DbtProject(project_dir=Path("path/to/dbt_project"))
# links to dbt model source code from assets
dagster_dbt_translator = DagsterDbtTranslator(
settings=DagsterDbtTranslatorSettings(enable_code_references=True)
)
@dbt_assets(
manifest=my_project.manifest_path,
dagster_dbt_translator=dagster_dbt_translator,
project=my_project,
)
def my_dbt_assets(context: AssetExecutionContext, dbt: DbtCliResource):
yield from dbt.cli(["build"], context=context).stream()
defs = Definitions(assets=with_source_code_references([my_dbt_assets]))
Customizing tags
In Dagster, tags are key-value pairs. However, in dbt, tags are strings. To bridge this divide, the dbt tag string is used as the Dagster tag key, and the Dagster tag value is set to the empty string, "". Any dbt tags that don't match Dagster's supported tag key format (e.g. they contain unsupported characters) will be ignored by default.
For dbt models, seeds, and snapshots, the default Dagster tags will be the dbt node's configured tags.
Any dbt tags that don't match Dagster's supported tag key format (e.g. they contain unsupported characters) will be ignored.
To override the Dagster tags for all dbt nodes in your dbt project, you can create a custom DagsterDbtTranslator and implement DagsterDbtTranslator.get_tags. The following converts dbt tags of the form foo=bar to key/value pairs:
from pathlib import Path
from dagster import AssetExecutionContext
from dagster_dbt import DagsterDbtTranslator, DbtCliResource, DbtProject, dbt_assets
from typing import Any
from collections.abc import Mapping
my_dbt_project = DbtProject(project_dir=Path("path/to/dbt_project"))
class CustomDagsterDbtTranslator(DagsterDbtTranslator):
def get_tags(self, dbt_resource_props: Mapping[str, Any]) -> Mapping[str, str]:
dbt_tags = dbt_resource_props.get("tags", [])
dagster_tags = {}
for tag in dbt_tags:
key, _, value = tag.partition("=")
dagster_tags[key] = value if value else ""
return dagster_tags
@dbt_assets(
manifest=my_dbt_project.manifest_path,
dagster_dbt_translator=CustomDagsterDbtTranslator(),
)
def my_dbt_assets(context: AssetExecutionContext, dbt: DbtCliResource):
yield from dbt.cli(["build"], context=context).stream()
Customizing automation conditions
To override the AutomationCondition generated for each dbt node in your dbt project, you can create a custom DagsterDbtTranslator and implement DagsterDbtTranslator.get_automation_condition. The following example defines AutomationCondition.eager as the condition for all dbt nodes:
from pathlib import Path
from dagster import AssetExecutionContext, AutomationCondition
from dagster_dbt import DagsterDbtTranslator, DbtCliResource, DbtProject, dbt_assets
from typing import Any
from collections.abc import Mapping
my_dbt_project = DbtProject(project_dir=Path("path/to/dbt_project"))
class CustomDagsterDbtTranslator(DagsterDbtTranslator):
def get_automation_condition(
self, dbt_resource_props: Mapping[str, Any]
) -> AutomationCondition | None:
return AutomationCondition.eager()
@dbt_assets(
manifest=my_dbt_project.manifest_path,
dagster_dbt_translator=CustomDagsterDbtTranslator(),
)
def my_dbt_assets(context: AssetExecutionContext, dbt: DbtCliResource):
yield from dbt.cli(["build"], context=context).stream()
Ensure that the default_automation_condition_sensor is enabled for automation conditions to be evaluated.
dbt models, code versions, and "Unsynced"
Note that Dagster allows the optional specification of a code_version for each asset definition, which is used to track changes. The code_version for an asset arising from a dbt model is defined automatically as the hash of the SQL defining the DBT model. This allows the asset graph in the UI to use the "Unsynced" status to indicate which dbt models have new SQL since they were last materialized.
Loading dbt tests as asset checks
Asset checks for dbt have been enabled by default, starting in dagster-dbt 0.23.0.
dbt-core 1.6 or later is required for full functionality.
Dagster automatically loads your dbt tests on models as asset checks. To load dbt tests on sources as asset checks as well, see Loading dbt source tests as asset checks section.
Indirect selection
Dagster uses dbt indirect selection to select dbt tests. By default, Dagster won't set DBT_INDIRECT_SELECTION so that the set of tests selected by Dagster is the same as the selected by dbt. When required, Dagster will override DBT_INDIRECT_SELECTION to empty in order to explicitly select dbt tests. For example:
- Materializing dbt assets and excluding their asset checks
- Executing dbt asset checks without materializing their assets
Singular tests
Dagster will load both generic and singular tests as asset checks. In the event that your singular test depends on multiple dbt models, you can use dbt metadata to specify which Dagster asset it should target. These fields can be filled in as they would be for the dbt ref function. The configuration can be supplied in a config block for the singular test.
{{
config(
meta={
'dagster': {
'ref': {
'name': 'customers',
'package': 'my_dbt_assets',
'version': 1,
},
}
}
)
}}
dbt-core version 1.6 or later is required for Dagster to read this metadata.
If this metadata isn't provided, Dagster won't ingest the test as an asset check. It will still run the test and emit a AssetObservation event with the test results.
Disabling asset checks
You can disable modeling your dbt tests as asset checks. The tests will still run and will be emitted as AssetObservation events. To do so you'll need to define a DagsterDbtTranslator with DagsterDbtTranslatorSettings that have asset checks disabled. The following example disables asset checks when using @dagster_dbt.dbt_assets:
from pathlib import Path
from dagster import AssetExecutionContext
from dagster_dbt import (
DagsterDbtTranslator,
DagsterDbtTranslatorSettings,
DbtCliResource,
DbtProject,
dbt_assets,
)
my_dbt_project = DbtProject(project_dir=Path("path/to/dbt_project"))
dagster_dbt_translator = DagsterDbtTranslator(
settings=DagsterDbtTranslatorSettings(enable_asset_checks=False)
)
@dbt_assets(
manifest=my_dbt_project.manifest_path,
dagster_dbt_translator=dagster_dbt_translator,
)
def my_dbt_assets(context: AssetExecutionContext, dbt: DbtCliResource):
yield from dbt.cli(["build"], context=context).stream()
Loading dbt source tests as asset checks
It's common to have the body of your dbt assets execute a dbt build command. In addition to executing all of your dbt models and their tests, this will also execute any dbt tests on sources that are upstream of your dbt models.
By default, Dagster does not load dbt source tests as asset checks. To enable this feature, you can define a DagsterDbtTranslator with DagsterDbtTranslatorSettings that have source tests enabled. The following example enables loading dbt source tests as asset checks:
from pathlib import Path
from dagster import AssetExecutionContext
from dagster_dbt import (
DagsterDbtTranslator,
DagsterDbtTranslatorSettings,
DbtCliResource,
DbtProject,
dbt_assets,
)
my_dbt_project = DbtProject(project_dir=Path("path/to/dbt_project"))
dagster_dbt_translator = DagsterDbtTranslator(
settings=DagsterDbtTranslatorSettings(enable_source_tests_as_checks=True)
)
@dbt_assets(
manifest=my_dbt_project.manifest_path,
dagster_dbt_translator=dagster_dbt_translator,
)
def my_dbt_assets(context: AssetExecutionContext, dbt: DbtCliResource):
yield from dbt.cli(["build"], context=context).stream()
Customizing asset materialization metadata
Dagster supports fetching additional metadata at dbt execution time to attach as materialization metadata, which is recorded each time your models are rebuilt and displayed in the Dagster UI.
Fetching row count data
To use this feature, you'll need to be on at least dagster>=0.17.6 and dagster-dbt>=0.23.6.
Dagster can automatically fetch row counts for dbt-generated tables and emit them as materialization metadata to be displayed in the Dagster UI.
Row counts are fetched in parallel to the execution of your dbt models. To enable this feature, call fetch_row_counts() on the core.dbt_cli_invocation.DbtEventIterator returned by the stream() dbt CLI call:
from pathlib import Path
from dagster import AssetExecutionContext
from dagster_dbt import DbtProject, DbtCliResource, dbt_assets
my_dbt_project = DbtProject(project_dir=Path("path/to/dbt_project"))
@dbt_assets(
manifest=my_dbt_project.manifest_path,
)
def my_dbt_assets(context: AssetExecutionContext, dbt: DbtCliResource):
yield from dbt.cli(["build"], context=context).stream().fetch_row_counts()
Once your dbt models have been materialized, you can view the row count data in the metadata table.
Fetching column-level metadata
To use this feature, you'll need to be on at least dagster>=1.8.0 and dagster-dbt>=0.24.0.
Dagster allows you to emit column-level metadata, like column schema and column lineage, as materialization metadata.
With this metadata, you can view documentation in Dagster for all columns, not just columns described in your dbt project.
Column-level metadata is fetched in parallel to the execution of your dbt models. To enable this feature, call fetch_column_metadata() on the core.dbt_cli_invocation.DbtEventIterator returned by the stream() dbt CLI call:
from pathlib import Path
from dagster import AssetExecutionContext
from dagster_dbt import DbtProject, DbtCliResource, dbt_assets
my_dbt_project = DbtProject(project_dir=Path("path/to/dbt_project"))
@dbt_assets(
manifest=my_dbt_project.manifest_path,
)
def my_dbt_assets(context: AssetExecutionContext, dbt: DbtCliResource):
yield from (
dbt.cli(["build"], context=context).stream().fetch_column_metadata()
)
Composing metadata fetching methods
Metadata fetching methods such as fetch_column_metadata() can be chained with other metadata fetching methods like fetch_row_counts():
from pathlib import Path
from dagster import AssetExecutionContext
from dagster_dbt import DbtProject, DbtCliResource, dbt_assets
my_dbt_project = DbtProject(project_dir=Path("path/to/dbt_project"))
@dbt_assets(
manifest=my_dbt_project.manifest_path,
)
def my_dbt_assets(context: AssetExecutionContext, dbt: DbtCliResource):
yield from (
dbt.cli(["build"], context=context)
.stream()
.fetch_row_counts()
.fetch_column_metadata()
)
Defining dependencies
Upstream dependencies
Defining a dbt source as a Dagster asset
Dagster parses information about assets that are upstream of specific dbt models from the dbt project itself. Whenever a model is downstream of a dbt source, that upstream source will be parsed as an upstream asset.
For example, if you defined a source in your sources.yml file like this:
sources:
- name: jaffle_shop
tables:
- name: orders
and use it in a model:
select *
from {{ source("jaffle_shop", "orders") }}
where foo=1
Then this model has an upstream source with the jaffle_shop/orders asset key.
In order to manage this upstream asset with Dagster, you can define it by passing the key into an asset definition via get_asset_key_for_source:
from dagster import asset, AssetExecutionContext
from dagster_dbt import DbtCliResource, get_asset_key_for_source, dbt_assets
@dbt_assets(manifest=MANIFEST_PATH)
def my_dbt_assets(context: AssetExecutionContext, dbt: DbtCliResource): ...
@asset(key=get_asset_key_for_source([my_dbt_assets], "jaffle_shop"))
def orders():
return ...
This allows you to change asset keys within your dbt project without having to update the corresponding Dagster definitions.
The get_asset_key_for_source method is used when a source has only one table. However, if a source contains multiple tables, like this example:
sources:
- name: clients_data
tables:
- name: names
- name: history
You can use define a @dg.multi_asset with keys from get_asset_keys_by_output_name_for_source instead:
from dagster import multi_asset, AssetOut, Output
from dagster_dbt import get_asset_keys_by_output_name_for_source
@multi_asset(
outs={
name: AssetOut(key=asset_key)
for name, asset_key in get_asset_keys_by_output_name_for_source(
[my_dbt_assets], "jaffle_shop"
).items()
}
)
def jaffle_shop(context: AssetExecutionContext):
output_names = list(context.op_execution_context.selected_output_names)
yield Output(value=..., output_name=output_names[0])
yield Output(value=..., output_name=output_names[1])
Defining an asset as an upstream data dependency of a dbt model
Dagster allows you to define existing assets as upstream data dependencies of dbt models, meaning that an upstream Dagster asset creates data for the dbt model to read. For example, say you have the following asset with asset key upstream:
from dagster import asset
@asset
def upstream(): ...
You can define that asset as a source in your sources.yml file:
sources:
- name: dagster
tables:
- name: upstream
Then, in the downstream model, you can select from this source data. This defines a data dependency relationship between your upstream asset and dbt model:
select *
from {{ source("dagster", "upstream") }}
where foo=1
Defining an asset as an upstream temporal dependency of a dbt model
Dagster allows you to define existing assets as upstream temporal dependencies of dbt models, meaning that Dagster needs to schedule the dbt model after a Dagster asset has materialized, but that the model does not need to read data from the asset. For example, say you have the following asset with asset key upstream:
from dagster import asset
@asset
def upstream(): ...
First, define that asset as a source in your sources.yml file:
sources:
- name: dagster
tables:
- name: upstream
Then, in the downstream model, you can specify that the downstream model depends on the upstream Dagster asset. This defines a temporal dependency relationship between your upstream asset and dbt model:
-- depends_on: {{ source('dagster','upstream') }}
SELECT ...
Downstream dependencies
Dagster allows you to define assets that are downstream of specific dbt models via get_asset_key_for_model. The below example defines my_downstream_asset as a downstream dependency of my_dbt_model:
from dagster_dbt import get_asset_key_for_model
from dagster import asset
@asset(deps=[get_asset_key_for_model([my_dbt_assets], "my_dbt_model")])
def my_downstream_asset(): ...
In the downstream asset, you may want direct access to the contents of the dbt model. To do so, you can customize the code within your @asset-decorated function to load upstream data.
Dagster alternatively allows you to delegate loading data to an I/O manager. For example, if you wanted to consume a dbt model with the asset key my_dbt_model as a Pandas dataframe, that would look something like the following:
from dagster_dbt import get_asset_key_for_model
from dagster import AssetIn, asset
@asset(
ins={
"my_dbt_model": AssetIn(
input_manager_key="pandas_df_manager",
key=get_asset_key_for_model([my_dbt_assets], "my_dbt_model"),
)
},
)
def my_downstream_asset(my_dbt_model):
# my_dbt_model is a Pandas dataframe
return my_dbt_model.where(foo="bar")
Building incremental models using partitions
You can define a Dagster PartitionsDefinition alongside dbt in order to build incremental models.
Partitioned assets will be able to access the TimeWindow's start and end dates, and these can be passed to dbt's CLI as variables which can be used to filter incremental models.
When a partition definition to passed to the @dagster_dbt.dbt_assets decorator, all assets are defined to operate on the same partitions. With this in mind, we can retrieve any time window from AssetExecutionContext.partition_time_window property in order to get the current start and end partitions.
import json
from pathlib import Path
from dagster import DailyPartitionsDefinition, OpExecutionContext
from dagster_dbt import DbtCliResource, DbtProject, dbt_assets
my_dbt_project = DbtProject(project_dir=Path("path/to/dbt_project"))
@dbt_assets(
manifest=my_dbt_project.manifest_path,
partitions_def=DailyPartitionsDefinition(start_date="2023-01-01"),
)
def partitionshop_dbt_assets(context: OpExecutionContext, dbt: DbtCliResource):
start, end = context.partition_time_window
dbt_vars = {"min_date": start.isoformat(), "max_date": end.isoformat()}
dbt_build_args = ["build", "--vars", json.dumps(dbt_vars)]
yield from dbt.cli(dbt_build_args, context=context).stream()
With the variables defined, we can now reference min_date and max_date in our SQL and configure the dbt model as incremental. Here, we define an incremental run to operate on rows with order_date that is between our min_date and max_date.
-- Configure the model as incremental, use a unique_key and the delete+insert strategy to ensure the pipeline is idempotent.
{{ config(materialized='incremental', unique_key='order_date', incremental_strategy="delete+insert") }}
select * from {{ ref('my_model') }}
-- Use the Dagster partition variables to filter rows on an incremental run
{% if is_incremental() %}
where order_date >= '{{ var('min_date') }}' and order_date <= '{{ var('max_date') }}'
{% endif %}