Run configuration
When you launch a job that materializes, executes, or instantiates a configurable entity, such as an asset, op, or resource, you can provide run configuration for that entity. Within the function that defines the entity, you can access the passed-in configuration through the config parameter. Typically, the provided run configuration values correspond to a configuration schema attached to the asset, op, or resource definition. Dagster validates the run configuration against the schema and proceeds only if validation is successful.
A common use of configuration is for a schedule or sensor to provide configuration to the job run it is launching. For example, a daily schedule might provide the day it's running on to one of the assets as a config value, and that asset might use that config value to decide what day's data to read.
The code examples in this guide conform to the project structure generated by the create-dagster project CLI command. For more information, see Creating Dagster projects.
Defining configurable parameters for an asset, op, or job
You can specify configurable parameters accepted by an asset, op, or job by defining a config model subclass of Config and a config parameter to the corresponding asset or op function. These config models utilize Pydantic, a popular Python library for data validation and serialization.
During execution, the specified config is accessed within the body of the asset, op, or job with the config parameter.
- Using assets
- Using ops and jobs
Here, we define a basic asset in assets.py and its configurable parameters in resources.py. MyAssetConfig is a subclass of Config that holds a single string value representing the name of a user. This config can be accessed through the config parameter in the asset body:
import dagster as dg
from .resources import MyAssetConfig # ty: ignore[unresolved-import]
@dg.asset
def greeting(config: MyAssetConfig) -> str:
return f"hello {config.person_name}"
import dagster as dg
class MyAssetConfig(dg.Config):
person_name: str
@dg.definitions
def resources() -> dg.Definitions:
return dg.Definitions(resources={"config": MyAssetConfig(person_name="")})
Here, we define a basic op in ops.py and its configurable parameters in resources.py. MyOpConfig is a subclass of Config that holds a single string value representing the name of a user. This config can be accessed through the config parameter in the op body:
import dagster as dg
from .resources import MyOpConfig # ty: ignore[unresolved-import]
@dg.op
def print_greeting(config: MyOpConfig):
print(f"hello {config.person_name}")
import dagster as dg
class MyOpConfig(dg.Config):
person_name: str
@dg.definitions
def resources() -> dg.Definitions:
return dg.Definitions(resources={"config": MyOpConfig(person_name="")})
You can also build config into jobs.
These examples showcase the most basic config types that can be used. For more information on the set of config types Dagster supports, see the advanced config types documentation.
Defining configurable parameters for a resource
Configurable parameters for a resource are defined by specifying attributes for a resource class, which subclasses ConfigurableResource. The below resource defines a configurable connection URL, which can be accessed in any methods defined on the resource:
import dagster as dg
class Engine:
def execute(self, query: str): ...
def get_engine(connection_url: str) -> Engine:
return Engine()
class MyDatabaseResource(dg.ConfigurableResource):
connection_url: str
def query(self, query: str):
return get_engine(self.connection_url).execute(query)
@dg.definitions
def resources() -> dg.Definitions:
return dg.Definitions(
resources={
# To send a query to the database, you can call my_db_resource.query("QUERY HERE")
# in the asset, op, or job where you reference my_db_resource
"my_db_resource": MyDatabaseResource(connection_url="")
}
)
For more information on using resources, see the External resources documentation.
Providing config values at runtime
To execute a job or materialize an asset that specifies config, you'll need to provide values for its parameters. How you provide these values depends on the interface you use: Python, the Dagster UI, or the command line (CLI).
- Python
- Dagster UI
- Command line
When specifying config from the Python API, you can use the run_config argument for JobDefinition.execute_in_process or materialize. This takes a RunConfig object, within which we can supply config on a per-op or per-asset basis. The config is specified as a dictionary, with the keys corresponding to the op/asset names and the values corresponding to the config values.
import dagster as dg
from .resources import MyAssetConfig # ty: ignore[unresolved-import]
@dg.asset
def greeting(config: MyAssetConfig) -> str:
return f"hello {config.person_name}"
asset_result = dg.materialize(
[greeting],
run_config=dg.RunConfig({"greeting": MyAssetConfig(person_name="Alice")}),
)
How you access the config editor depends on whether you're working with a job or an asset:
- Jobs: Navigate to the job and open the Launchpad tab to supply config as YAML.
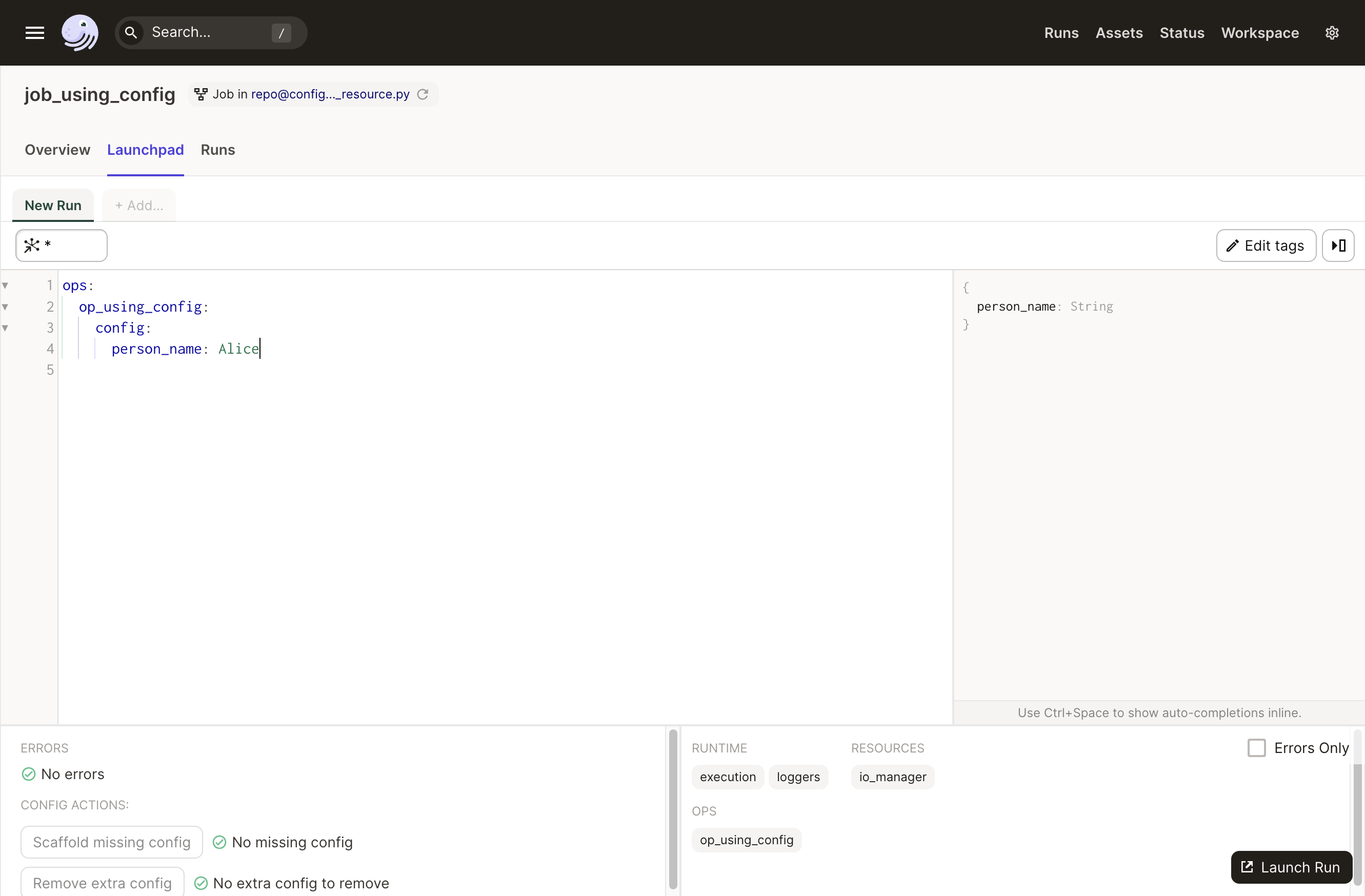
- Assets: Click the dropdown arrow next to the Materialize button and select Open launchpad. If an asset has a defined
config, a launchpad modal will also appear automatically when you click Materialize.
In both cases, the YAML schema matches the layout of the defined config class. The editor has typeahead, schema validation, and schema documentation. You can also click the Scaffold Missing Config button to generate dummy values based on the config schema.
When executing a job from Dagster's CLI with dg launch --job, you can put config in a YAML file:
ops:
op_using_config:
config:
person_name: Alice
And then pass the file path with the --config option:
dg launch --job my_job --config my_config.yaml
Using environment variables with config
Assets and ops can be configured using environment variables by passing an EnvVar when constructing a config object. This is useful when the value is sensitive or may vary based on environment. If using Dagster+, environment variables can be set up directly in the UI.
import dagster as dg
from .resources import MyAssetConfig # ty: ignore[unresolved-import]
@dg.asset
def greeting(config: MyAssetConfig) -> str:
return f"hello {config.person_name}"
asset_result = dg.materialize(
[greeting],
run_config=dg.RunConfig(
{"greeting": MyAssetConfig(person_name=dg.EnvVar("PERSON_NAME"))}
),
)
For more information on using environment variables in Dagster, see Using environment variables and secrets in Dagster code.
Validation
Dagster validates any provided run config against the corresponding Pydantic model. It will abort execution with a DagsterInvalidConfigError or Pydantic ValidationError if validation fails. For example, both of the following will fail, because there is no nonexistent_config_value in the config schema:
import dagster as dg
from .resources import MyAssetConfig # ty: ignore[unresolved-import]
@dg.asset
def greeting(config: MyAssetConfig) -> str:
return f"hello {config.person_name}"
asset_result = dg.materialize(
[greeting],
run_config=dg.RunConfig({"greeting": MyAssetConfig(nonexistent_config_value=1)}),
)
Next steps
Config is a powerful tool for making Dagster pipelines more flexible and observable. For a deeper dive into the supported config types, see the advanced config types documentation. For more information on using resources, which are a powerful way to encapsulate reusable logic, see the resources documentation.