Intro to ops and jobs, part one: Write a single-op job#
In this guide, we'll touch on Dagster ops and jobs. Ops are individual units of computation that we wire together to form jobs.
In this part, you'll:
Step 1: Write your first op#
Let's write our first Dagster op and save it as hello.py.
Typically, you'll define ops by annotating ordinary Python functions with the @op decorator.
Our first op finds the sizes of all the files in our current directory and logs them.
import os from dagster import job, op, get_dagster_logger @op def get_file_sizes(): files = [f for f in os.listdir(".") if os.path.isfile(f)] for f in files: get_dagster_logger().info(f"Size of {f} is {os.path.getsize(f)}")
In this simple case, our op takes no arguments, and also returns no outputs. Don't worry, we'll soon encounter ops that are more dynamic.
Step 2: Write your first job#
To execute our op, we'll embed it in an equally simple job. A job is a set of ops arranged into a DAG of computation. You'll typically define jobs by annotating ordinary Python functions with the @job decorator.
@job def file_sizes_job(): get_file_sizes()
Here you'll see that we call get_file_sizes(). This call doesn't actually execute the op. Within the bodies of functions decorated with @job, we use function calls to indicate the dependency structure of the op making up the job. Here, we indicate that the execution of get_file_sizes doesn't depend on any other ops by calling it with no arguments.
Step 3: Execute your first job#
Assuming you’ve saved this job as hello.py, you can execute it via any of three different mechanisms:
Dagster UI#
To visualize your job (which only has one op) in the UI, just run the following. Make sure you're in the directory in which you've saved the job file:
dagster dev -f hello.py
You'll see output like:
Serving dagster-webserver on http://127.0.0.1:3000 in process 70635
You should be able to navigate to http://127.0.0.1:3000 in your web browser and view your job. It isn't very interesting yet, because it only has one op.
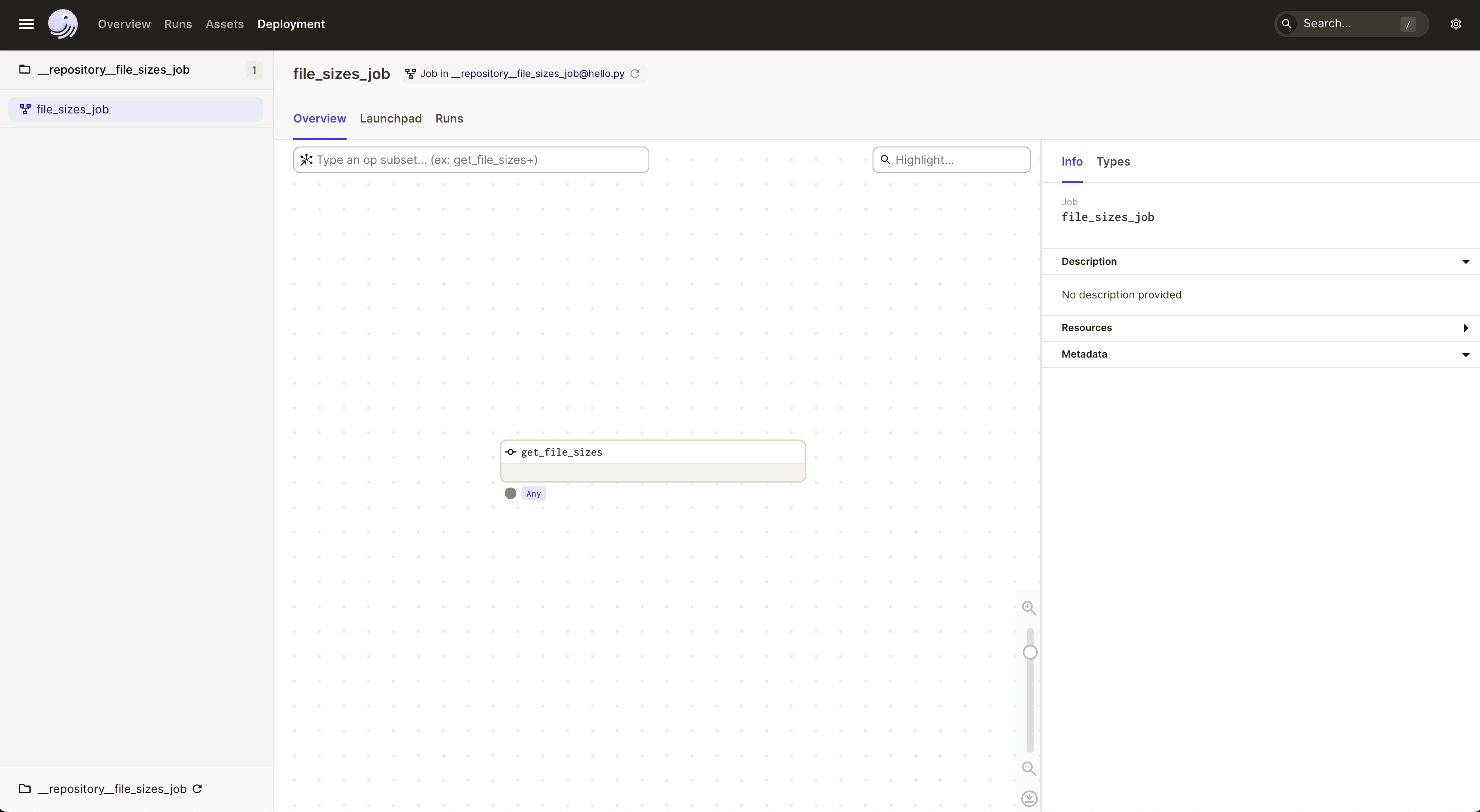
Click on the Launchpad tab and you'll see the view below.
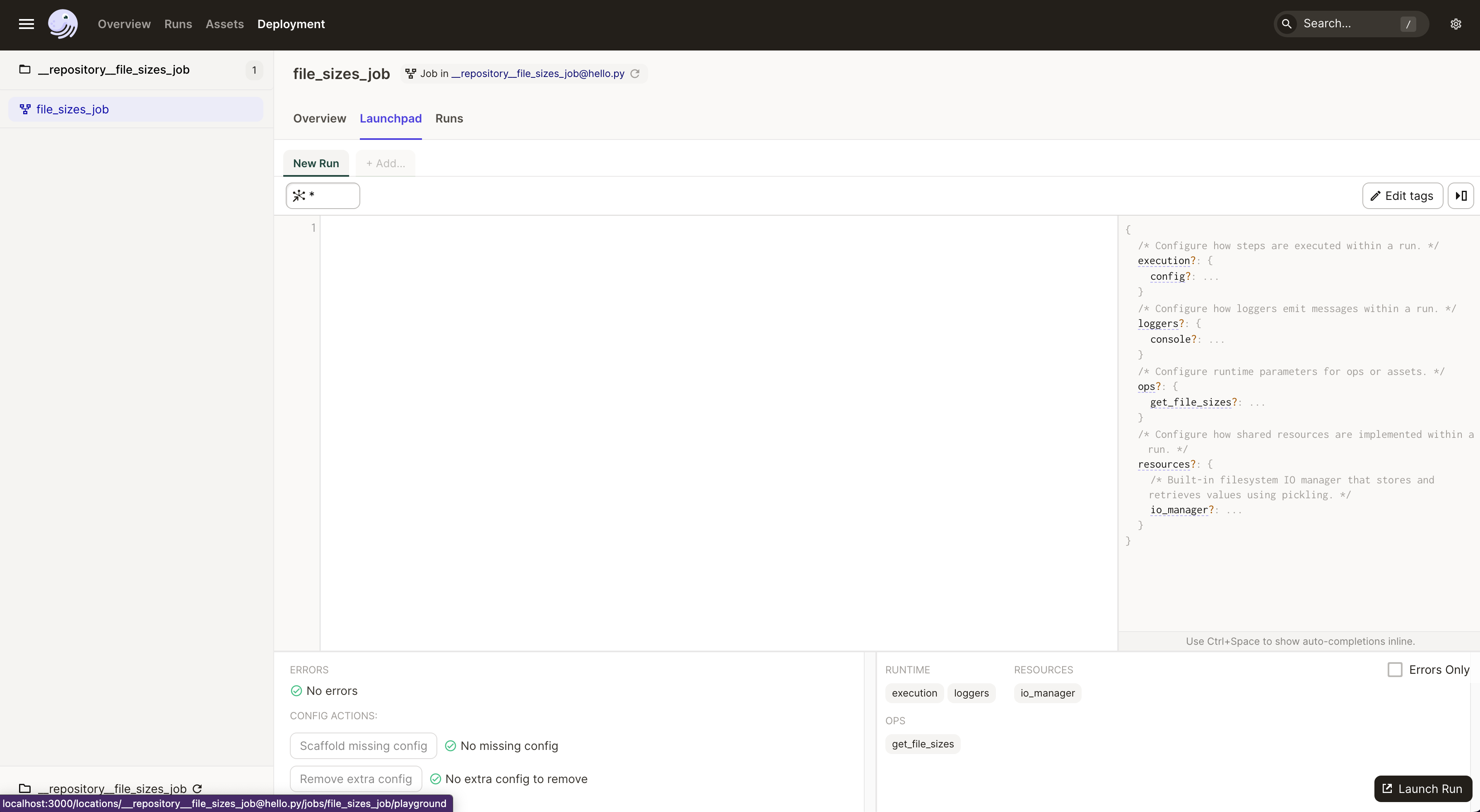
The large upper left pane is empty here, but, in jobs with parameters, this is where you'll be able to edit job configuration on the fly.
Click the Launch Run button on the bottom right to execute this job directly from the UI. A new window should open, and you'll see a much more structured view of the stream of Dagster events start to appear in the left-hand pane.
If you have pop-up blocking enabled, you may need to tell your browser to allow pop-ups from 127.0.0.1—or, just navigate to the Runs tab to see this, and every run of your job.
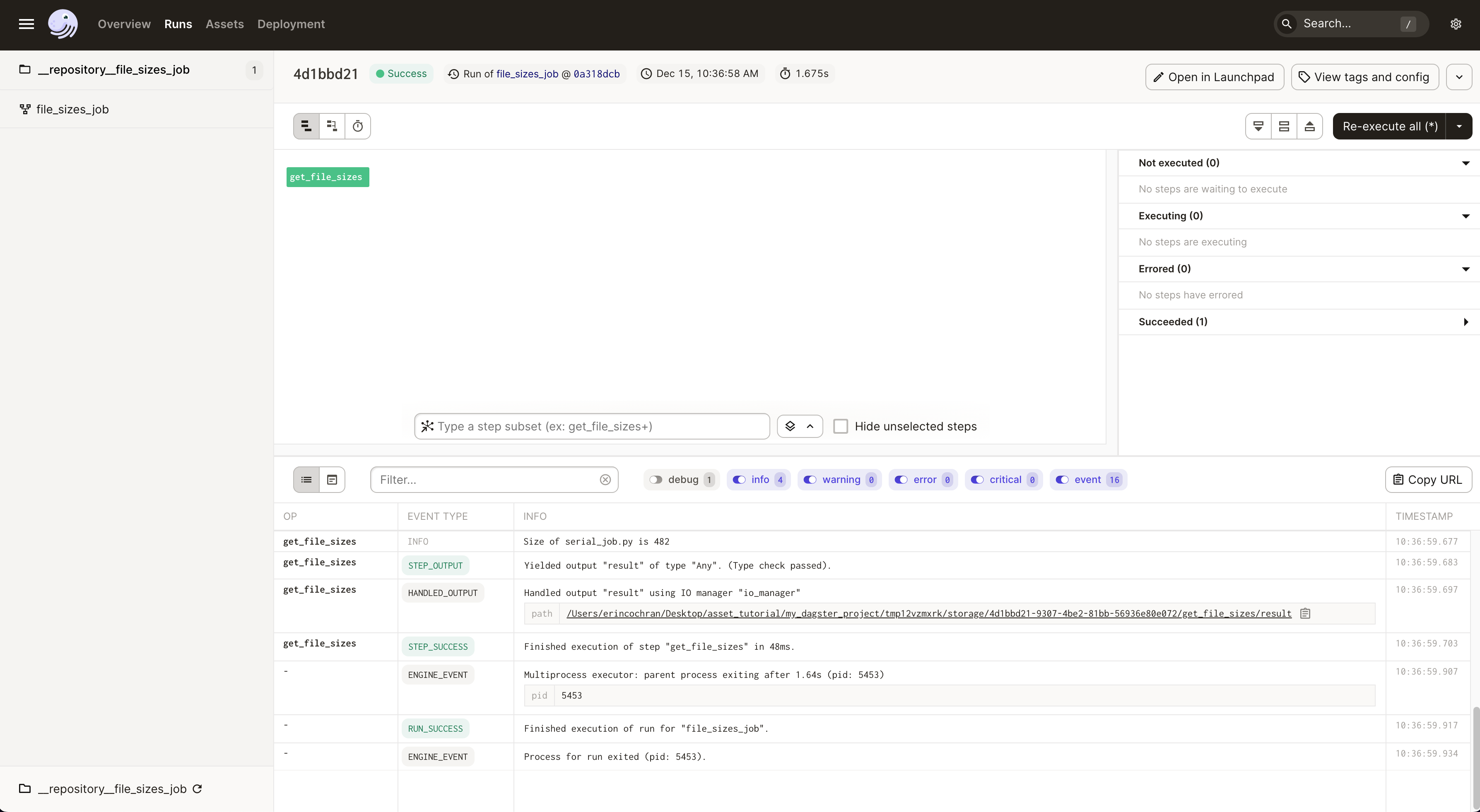
In this view, you can filter and search through the logs corresponding to your job run.
What's next?#
At this point, you should have an executed job that contains a single op. The next step is to connect a series of ops in a job.