Pandas & Dagster
This feature is considered in a beta stage. It is still being tested and may change.
This page describes the dagster-pandas library, which is used for performing data validation. To simply use pandas with Dagster, start with the Dagster Quickstart
Dagster makes it easy to use pandas code to manipulate data and then store that data in other systems such as files on Amazon S3 or tables in Snowflake
- Creating Dagster DataFrame Types
- Dagster DataFrame Level Validation
- Dagster DataFrame Summary Statistics
The dagster_pandas library provides the ability to perform data validation, emit summary statistics, and enable reliable dataframe serialization/deserialization. On top of this, the Dagster type system generates documentation of your dataframe constraints and makes it accessible in the Dagster UI.
Creating Dagster DataFrame Types
To create a custom dagster_pandas type, use create_dagster_pandas_dataframe_type and provide a list of PandasColumn objects which specify column-level schema and constraints. For example, we can construct a custom dataframe type to represent a set of e-bike trips in the following way:
TripDataFrame = create_dagster_pandas_dataframe_type(
name="TripDataFrame",
columns=[
PandasColumn.integer_column("bike_id", min_value=0),
PandasColumn.categorical_column("color", categories={"red", "green", "blue"}),
PandasColumn.datetime_column(
"start_time", min_datetime=Timestamp(year=2020, month=2, day=10)
),
PandasColumn.datetime_column(
"end_time", min_datetime=Timestamp(year=2020, month=2, day=10)
),
PandasColumn.string_column("station"),
PandasColumn.exists("amount_paid"),
PandasColumn.boolean_column("was_member"),
],
)
Once our custom data type is defined, we can use it as the type declaration for the inputs / outputs of our ops:
@op(out=Out(TripDataFrame))
def load_trip_dataframe() -> DataFrame:
return read_csv(
file_relative_path(__file__, "./ebike_trips.csv"),
parse_dates=["start_time", "end_time"],
date_parser=lambda x: datetime.strptime(x, "%Y-%m-%d %H:%M:%S.%f"),
dtype={"color": "category"},
)
By passing in these PandasColumn objects, we are expressing the schema and constraints we expect our dataframes to follow when Dagster performs type checks for our ops. Moreover, if we go to the op viewer, we can follow our schema documented in the UI:
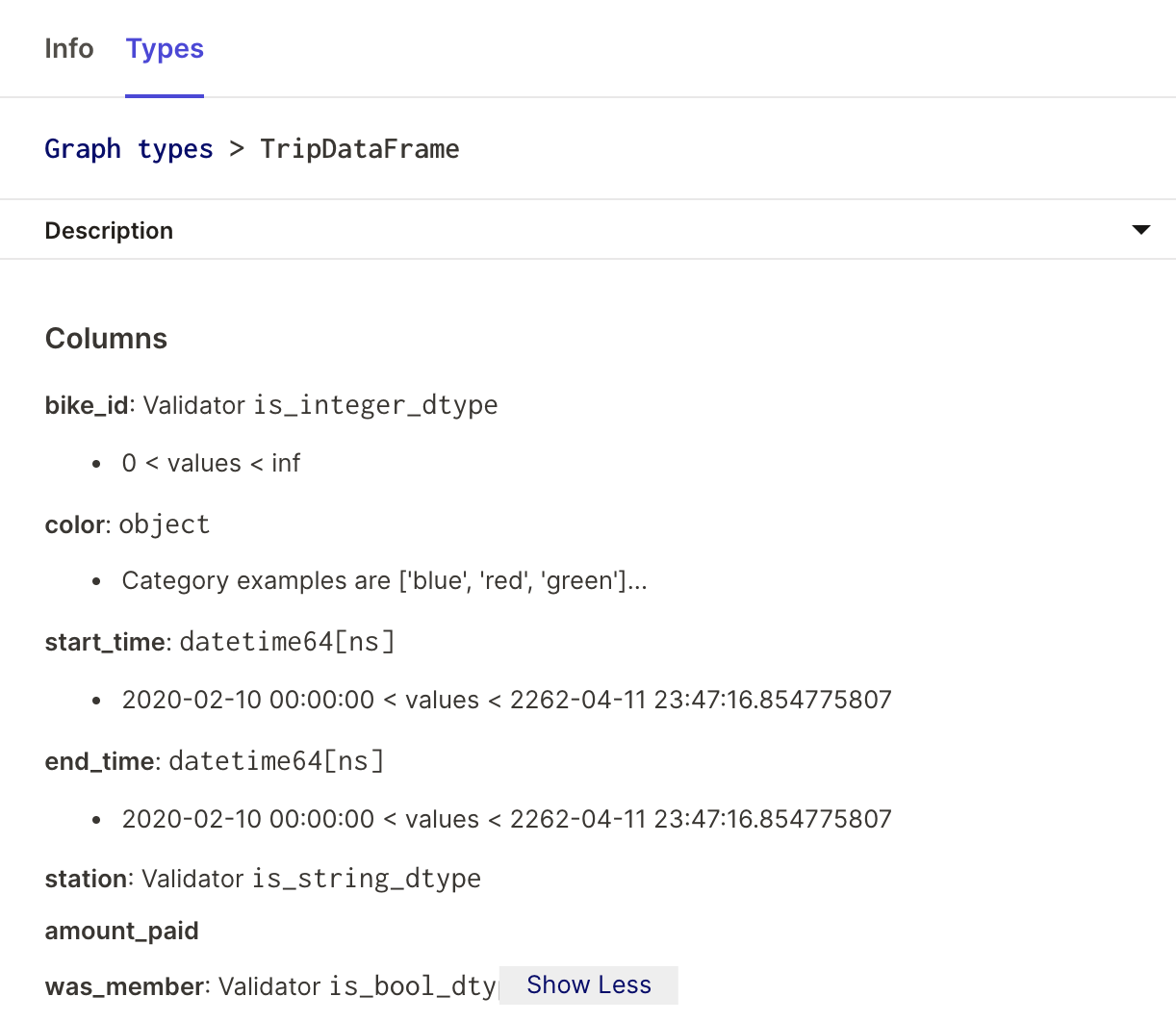
Dagster DataFrame Level Validation
Now that we have a custom dataframe type that performs schema validation during a run, we can express dataframe level constraints (e.g number of rows, or columns).
To do this, we provide a list of dataframe constraints to create_dagster_pandas_dataframe_type; for example, using RowCountConstraint. More information on the available constraints can be found in the dagster_pandas API docs.
This looks like:
ShapeConstrainedTripDataFrame = create_dagster_pandas_dataframe_type(
name="ShapeConstrainedTripDataFrame", dataframe_constraints=[RowCountConstraint(4)]
)
If we rerun the above example with this dataframe, nothing should change. However, if we pass in 100 to the row count constraint, we can watch our job fail that type check.
Dagster DataFrame Summary Statistics
Aside from constraint validation, create_dagster_pandas_dataframe_type also takes in a summary statistics function that emits metadata dictionaries which are surfaced during runs. Since data systems seldom control the quality of the data they receive, it becomes important to monitor data as it flows through your systems. In complex jobs, this can help debug and monitor data drift over time. Let's illustrate how this works in our example:
def compute_trip_dataframe_summary_statistics(dataframe):
return {
"min_start_time": min(dataframe["start_time"]).strftime("%Y-%m-%d"),
"max_end_time": max(dataframe["end_time"]).strftime("%Y-%m-%d"),
"num_unique_bikes": str(dataframe["bike_id"].nunique()),
"n_rows": len(dataframe),
"columns": str(dataframe.columns),
}
SummaryStatsTripDataFrame = create_dagster_pandas_dataframe_type(
name="SummaryStatsTripDataFrame",
metadata_fn=compute_trip_dataframe_summary_statistics,
)
Now if we run this job in the UI launchpad, we can see that the SummaryStatsTripDataFrame type is displayed in the logs along with the emitted metadata.
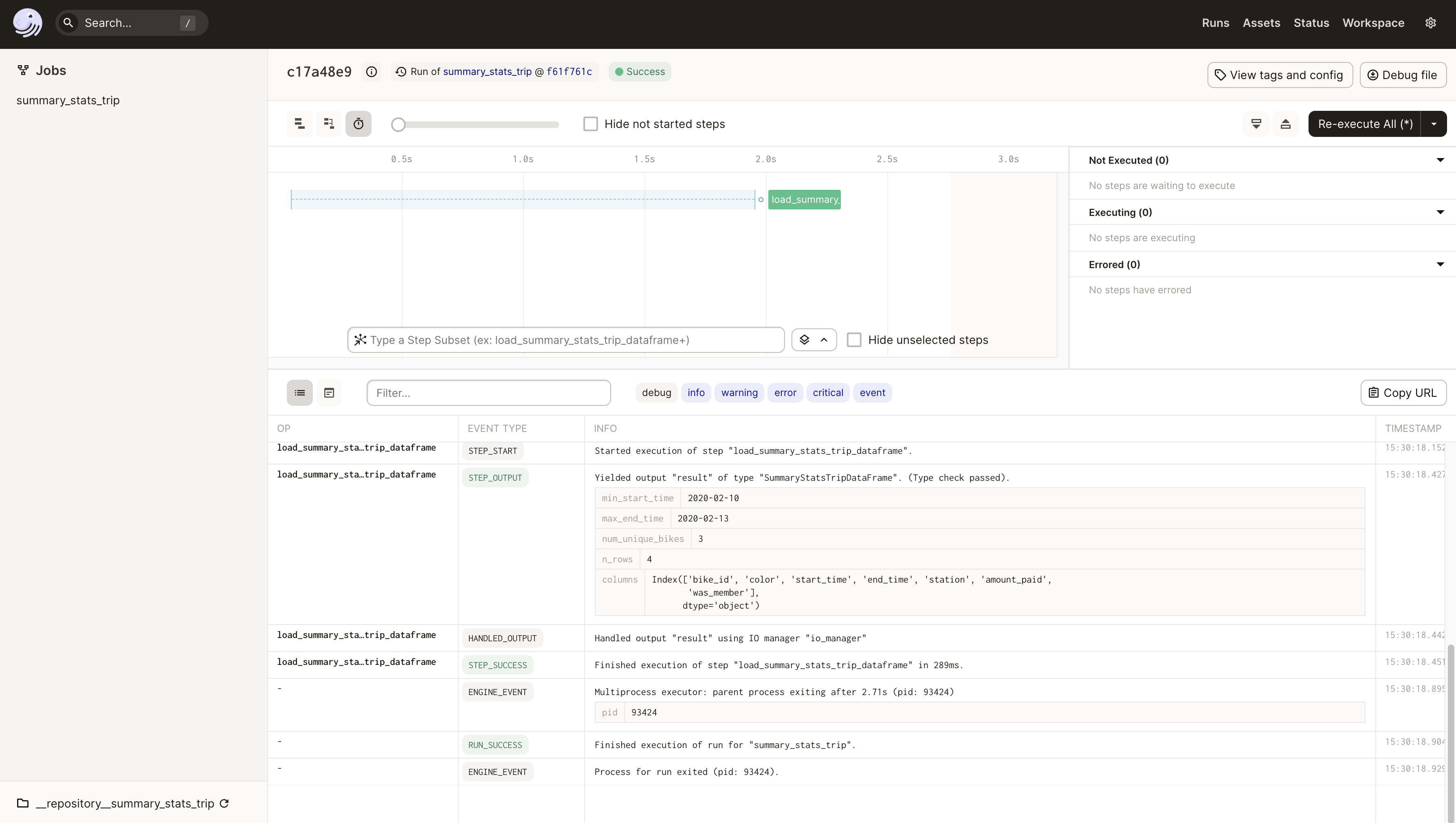
Dagster DataFrame Custom Validation
PandasColumn is user-pluggable with custom constraints. They can be constructed directly and passed a list of ColumnConstraint objects.
To tie this back to our example, let's say that we want to validate that the amount paid for a e-bike must be in 5 dollar increments because that is the price per mile rounded up. As a result, let's implement a DivisibleByFiveConstraint. To do this, all it needs is a markdown_description for the UI which accepts and renders markdown syntax, an error_description for error logs, and a validation method which throws a ColumnConstraintViolationException if a row fails validation. This would look like the following:
class DivisibleByFiveConstraint(ColumnConstraint):
def __init__(self):
message = "Value must be divisible by 5"
super().__init__(error_description=message, markdown_description=message)
def validate(self, dataframe, column_name):
rows_with_unexpected_buckets = dataframe[
dataframe[column_name].apply(lambda x: x % 5 != 0)
]
if not rows_with_unexpected_buckets.empty:
raise ColumnConstraintViolationException(
constraint_name=self.name,
constraint_description=self.error_description,
column_name=column_name,
offending_rows=rows_with_unexpected_buckets,
)
CustomTripDataFrame = create_dagster_pandas_dataframe_type(
name="CustomTripDataFrame",
columns=[
PandasColumn(
"amount_paid",
constraints=[
ColumnDTypeInSetConstraint({"int64"}),
DivisibleByFiveConstraint(),
],
)
],
)