Quickstart#
Welcome to Dagster! This guide will help you quickly run the Dagster Quickstart project, showcasing Dagster's capabilities and serving as a foundation for exploring its features.
The Dagster Quickstart project can be used without installing anything on your machine by using the pre-configured GitHub Codespace. If you prefer to run things on your own machine, however, we've got you covered.
Option 1: Running Locally#
Dagster supports Python 3.9 through 3.12.
Ensure you have one of the supported Python versions installed before proceeding.
Refer to Python's official getting started guide, or our recommendation of using pyenv for installing Python.
Clone the Dagster Quickstart repository by executing:
git clone https://github.com/dagster-io/dagster-quickstart && cd dagster-quickstartInstall the necessary dependencies using the following command:
We use
-eto install dependencies in "editable mode". This allows changes to be automatically applied when we modify code.pip install -e ".[dev]"Run the project!
dagster devNavigate to localhost:3000 in your web browser.
Success!
Navigating the User Interface#
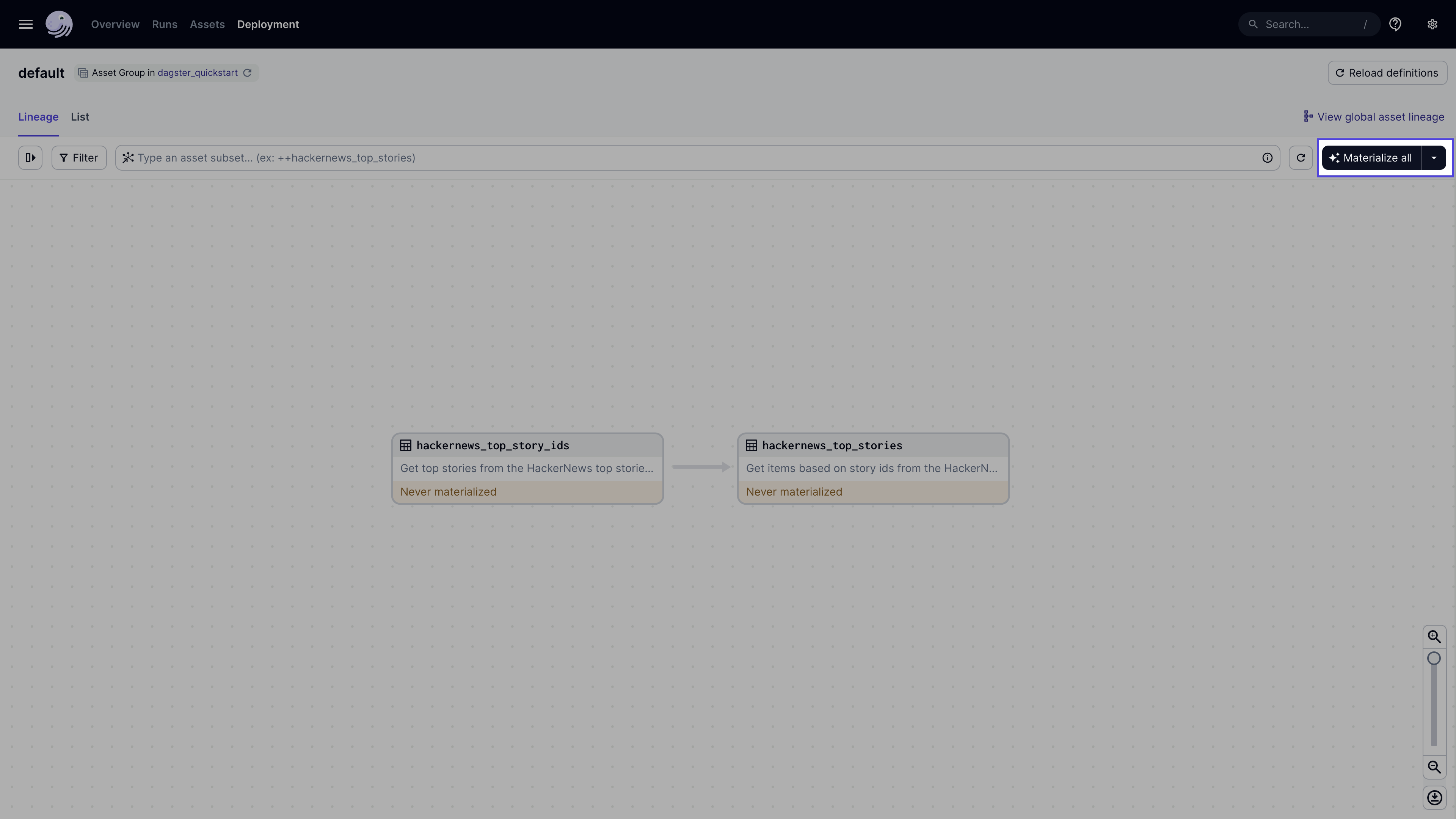
You should now have a running instance of Dagster! From here, we can run our data pipeline.
To run the pipeline, click the Materialize All button in the top right. In Dagster, materialization refers to executing the code associated with an asset to produce an output.
Congratulations! You have successfully materialized two Dagster assets:
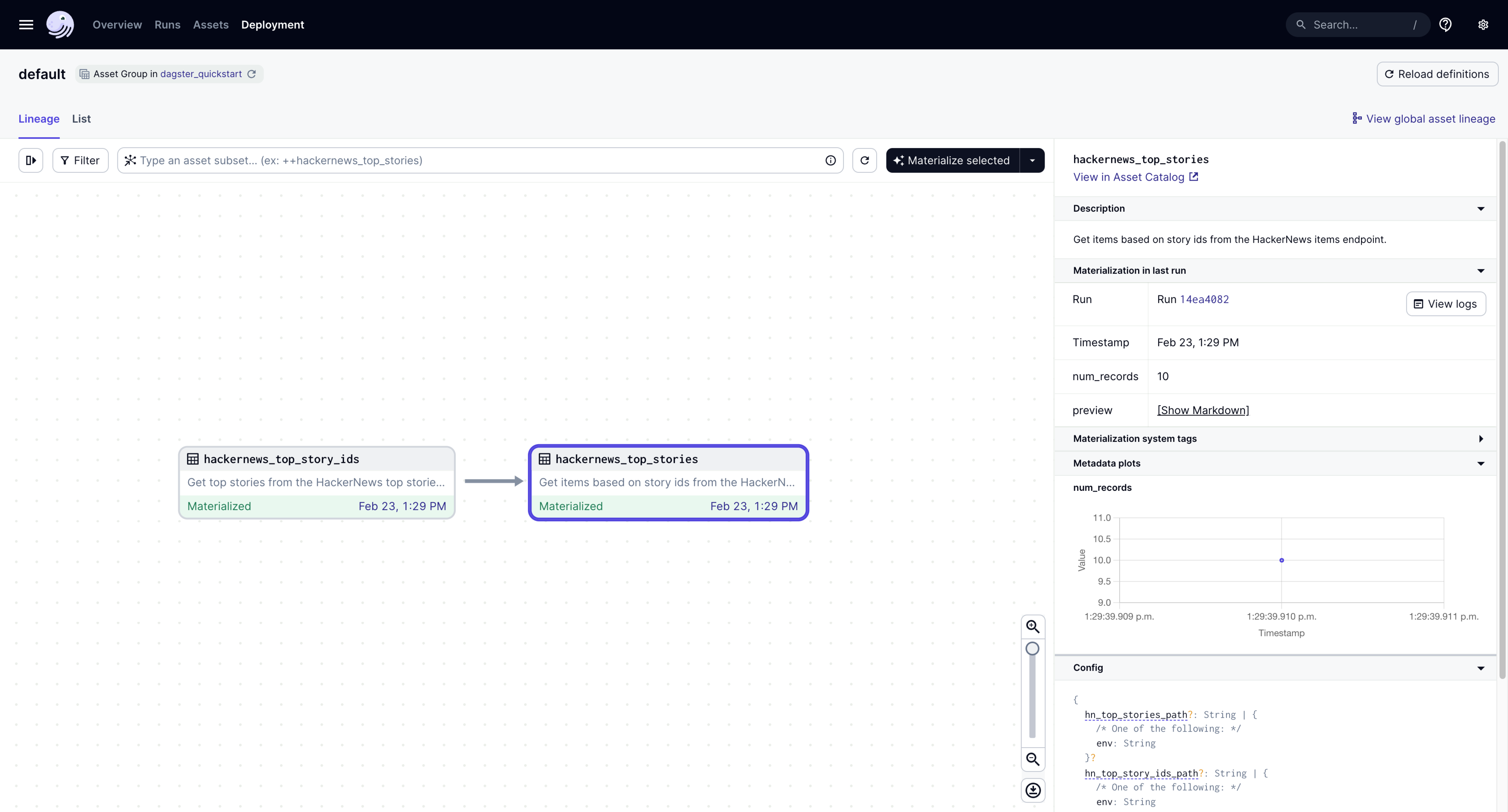
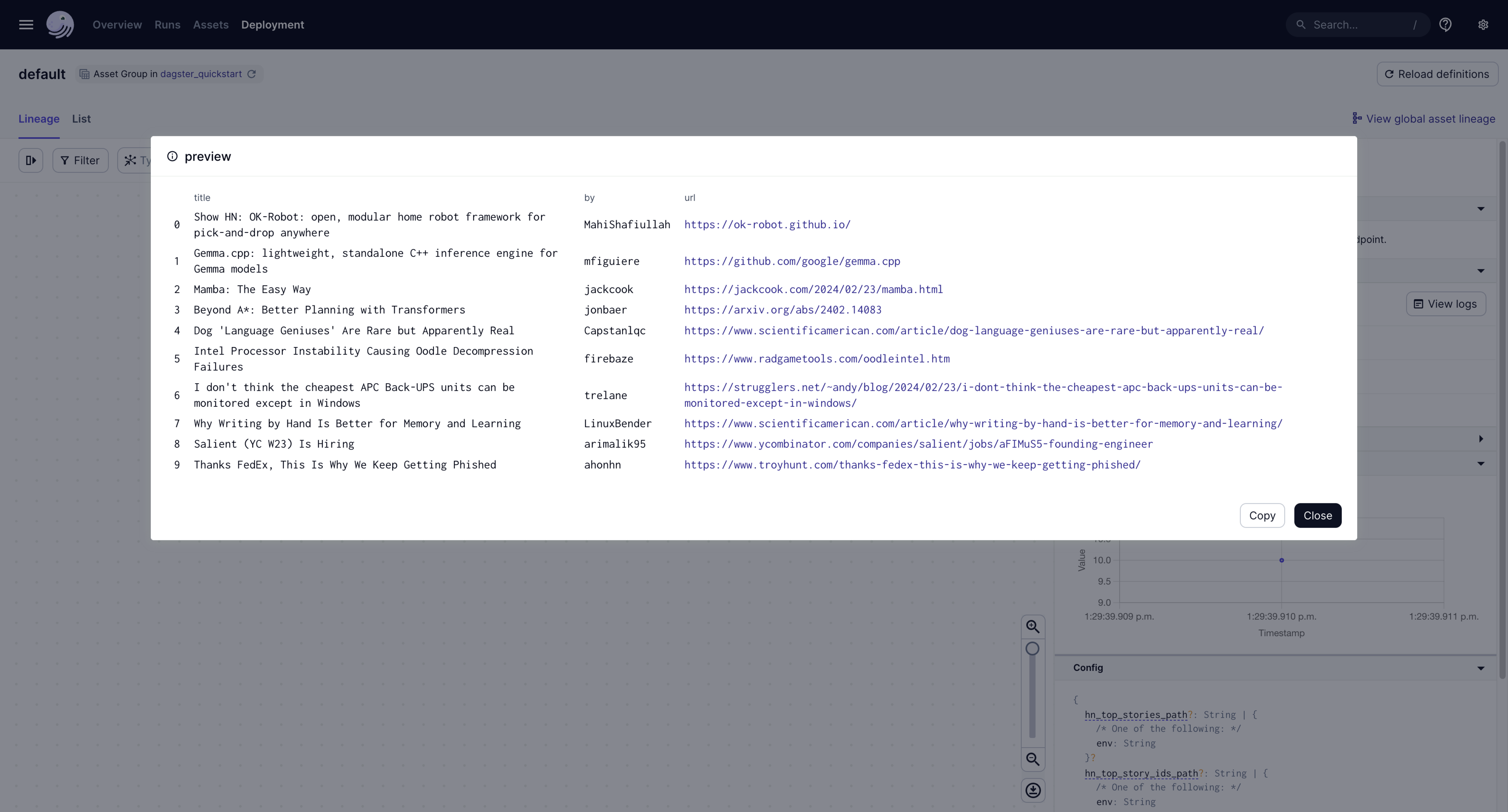
But wait - there's more. Because the hackernews_top_stories asset returned some metadata, you can view the metadata right in the UI:
- Click the asset
- In the sidebar, click the Show Markdown link in the Materialization in Last Run section. This opens a preview of the pipeline result, allowing you to view the top 10 HackerNews stories:
Understanding the Code#
The Quickstart project defines two Assets using the @asset decorator:
hackernews_top_story_idsretrieves the top stories from the Hacker News API and saves them as a JSON file.hackernews_top_storiesasset builds upon the first asset, retrieving data for each story as a CSV file, and returns aMaterializeResultwith a markdown preview of the top stories.
import json import pandas as pd import requests from dagster import Config, MaterializeResult, MetadataValue, asset class HNStoriesConfig(Config): top_stories_limit: int = 10 hn_top_story_ids_path: str = "hackernews_top_story_ids.json" hn_top_stories_path: str = "hackernews_top_stories.csv" @asset def hackernews_top_story_ids(config: HNStoriesConfig): """Get top stories from the HackerNews top stories endpoint.""" top_story_ids = requests.get( "https://hacker-news.firebaseio.com/v0/topstories.json" ).json() with open(config.hn_top_story_ids_path, "w") as f: json.dump(top_story_ids[: config.top_stories_limit], f) @asset(deps=[hackernews_top_story_ids]) def hackernews_top_stories(config: HNStoriesConfig) -> MaterializeResult: """Get items based on story ids from the HackerNews items endpoint.""" with open(config.hn_top_story_ids_path, "r") as f: hackernews_top_story_ids = json.load(f) results = [] for item_id in hackernews_top_story_ids: item = requests.get( f"https://hacker-news.firebaseio.com/v0/item/{item_id}.json" ).json() results.append(item) df = pd.DataFrame(results) df.to_csv(config.hn_top_stories_path) return MaterializeResult( metadata={ "num_records": len(df), "preview": MetadataValue.md(str(df[["title", "by", "url"]].to_markdown())), } )
Next steps#
Congratulations on successfully running your first Dagster pipeline! In this example, we used assets, which are a cornerstone of Dagster projects. They empower data engineers to:
- Think in the same terms as stakeholders
- Answer questions about data quality and lineage
- Work with the modern data stack (dbt, Airbyte/Fivetran, Spark)
- Create declarative freshness policies instead of task-driven cron schedules
Dagster also offers ops and jobs, but we recommend starting with assets.
To create your own project, consider the following options:
- Scaffold a new project using our new project guide.
- Begin with an official example, like the dbt & Dagster project, and explore all examples on GitHub.