Best practices for managing a dbt project
With most of the integration logic in place, this final section covers best practices for managing a combined Dagster+ dbt pipeline, focusing on partitioning and dependency management.
Handling multiple partitions�
Both the taxi_trips asset and the dbt-generated assets are partitioned over time, but they don’t need to use the same partitioning scheme.
taxi_tripsingests monthly files, so a monthly partitioning strategy makes sense.- dbt models can run more frequently (for example, daily) to deliver fresher analytical outputs.
To support this, the codebase defines two partition definitions over the same time range:
monthly_partition– used by thetaxi_tripsasset.daily_partition– used byget_dbt_partitioned_models.
import dagster as dg
START_DATE = "2023-01-01"
END_DATE = "2023-04-01"
daily_partition = dg.DailyPartitionsDefinition(start_date=START_DATE, end_date=END_DATE)
monthly_partition = dg.MonthlyPartitionsDefinition(start_date=START_DATE, end_date=END_DATE)
This design lets you control ingestion and transformation frequency independently, while still preserving upstream/downstream relationships.
In the asset graph, you can see this difference:
taxi_tripsreferences 3 partitions (e.g., 2024-05, 2024-06, 2024-07).- dbt assets reference 90 partitions (one per day across those 3 months).
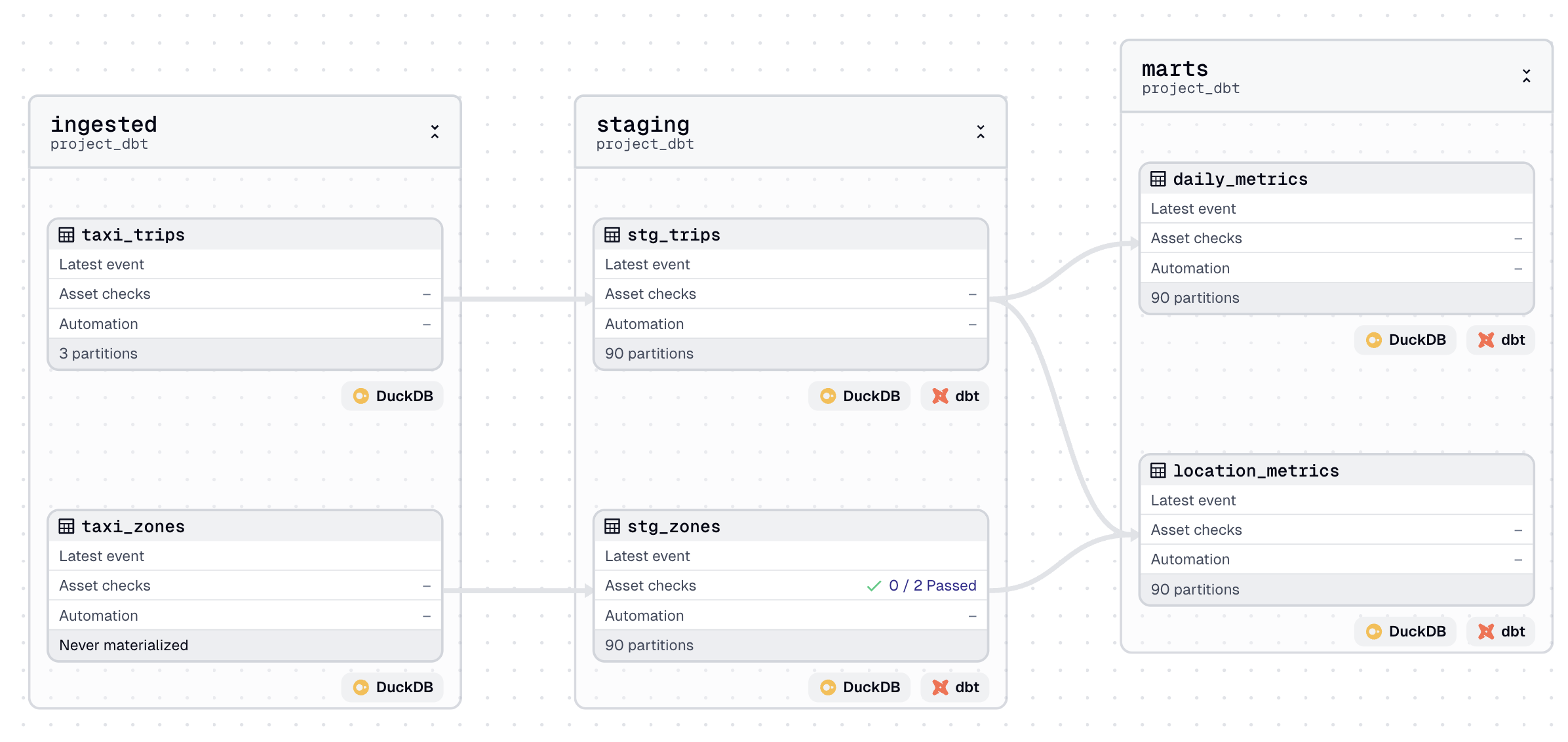
When executing Dagster assets, you can only materialize subsets of the graph that share the same partition definition. Because of this, it’s best to separate automation logic between ingestion and transformation layers, especially when they use different granularities.
Downstream assets
Earlier, we used a translator to align upstream Dagster assets (like taxi_trips) with their dbt sources (trips). This ensured accurate lineage across boundaries.
If you want to define downstream assets that depend on dbt models, you don’t need to re-declare those dbt assets. Instead, simply reference their asset keys in your downstream definitions. Dagster automatically registers all dbt models as assets during parsing, even if they weren’t manually declared in your code.
This makes it easy to integrate hand coded and dbt-derived assets in the same graph:
import dagster as dg
from dagster_duckdb import DuckDBResource
@dg.asset(
deps=[dg.AssetKey(["daily_metrics"])],
kinds={"duckdb"},
)
def manhattan_stats(database: DuckDBResource) -> dg.MaterializeResult:
query = """
select count(*)
from daily_metrics
"""
with database.get_connection() as conn:
count = conn.execute(query).fetchone()[0]
return dg.MaterializeResult(metadata={"table_count": dg.MetadataValue.int(count)})
You can also list all available Dagster asset keys to confirm model names, check dependencies, or debug execution plans.