Dagster OSS deployment architecture
This page covers general information about deploying Dagster OSS on your own infrastructure. For guides on specific platforms, see the deployment options documentation. For Dagster+ deployments, see the Dagster+ documentation.
Let's take a look at a generic Dagster deployment, after which we'll walk through each of its components:
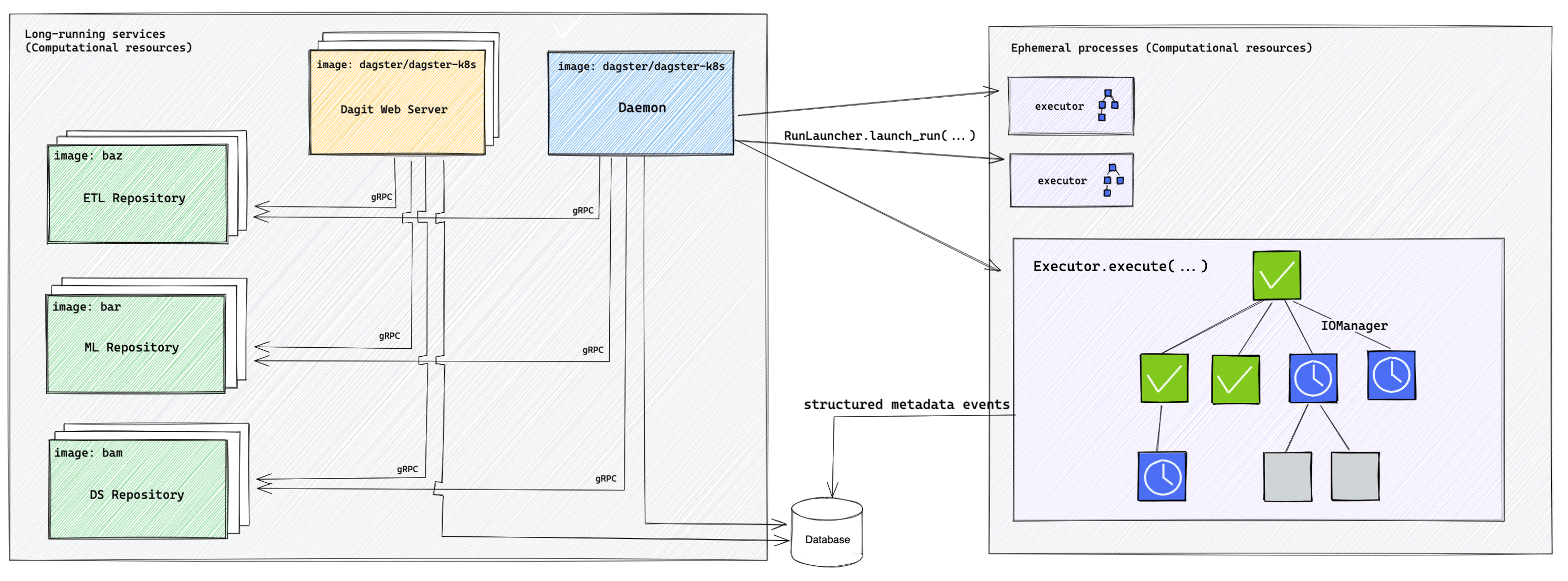
Long-running services
Dagster requires three long-running services, which are outlined in the table below:
| Service | Description | Replicas |
|---|---|---|
| Dagster webserver | dagster-webserver serves the user interface and responds to GraphQL queries. | The Dagster webserver can have one or more replicas. |
| Dagster daemon | The Dagster daemon operates schedules, sensors, and run queuing. | Not supported. |
| Code location server | Code location servers serve metadata about the collection of its Dagster definitions. | You can have many code location servers, but each code location can only have one replica for its server. |
Deployment configuration
Dagster OSS deployments are composed of multiple components, such as storages, executors, and run launchers. One of the core features of Dagster is that each of these components is swappable and configurable. If custom configuration isn't provided, Dagster will automatically use a default implementation of each component. For example, by default Dagster uses SqliteRunStorage to store information about pipeline runs. This can be swapped with the Dagster-provided PostgresRunStorage instead or or a custom storage class.
Based on the component's scope, configuration occurs at either the Dagster instance or Job run level. Access to user code is configured at the Workspace level. Refer to the following table for info on how components are configured at each of these levels:
| Level | Configuration | Description |
|---|---|---|
| Dagster instance | dagster.yaml | The Dagster instance is responsible for managing all deployment-wide components, such as the database. You can specify the configuration for instance-level components in dagster.yaml. |
| Workspace | workspace.yaml | Workspace files define how to access and load your code. You can define workspace configuration using workspace.yaml. |
| Job run | Run config | A job run is responsible for managing all job-scoped components, such as the executor, ops, and resources. These components dictate job behavior, such as how to execute ops or where to store outputs. Configuration for run-level components is specified using the job run's run config, and defined in either Python code or in the UI launchpad. |
Dagster provides a few vertically-integrated deployment options that abstract away some of the configuration options described above. For example, with Dagster's provided Kubernetes Helm chart deployment, configuration is defined through Helm values, and the Kubernetes deployment automatically generates Dagster Instance and Workspace configuration.
Job execution flow
Job execution flows through several parts of the Dagster system. The following table describes runs launched by the UI, specifically the components that handle execution and the order in which they are executed.
| Order | Component | Description | Configured by |
|---|---|---|---|
| Run coordinator | The run coordinator is a class invoked by the webserver process when runs are launched from the Dagster UI. This class can be configured to pass runs to the daemon via a queue. | Instance | |
| Run launcher | The run launcher is a class invoked by the daemon when it receives a run from the queue. This class initializes a new run worker to handle execution. Depending on the launcher, this could mean spinning up a new process, container, Kubernetes pod, etc. | Instance | |
| Run worker | The run worker is a process which traverses a graph and uses the executor to execute each op. | n/a | |
| Executor | The executor is a class invoked by the run worker for running user ops. Depending on the executor, ops run in local processes, new containers, Kubernetes pods, etc. | Run config |
Additionally, note that runs launched by schedules and sensors go through the same flow, but the first step is called by the Dagster daemon instead of the webserver.
In a deployment without the Dagster daemon, the webserver directly calls the run launcher and skips the run coordinator.