Using Celery with Kubernetes
In addition to using the k8s_job_executor to run each op in its own Kubernetes job, Dagster also allows you to use Celery to limit the number of ops that can concurrently connect to a resource across all running Dagster jobs.
In this section, we demonstrate how to extend the previous Helm deployment guide to support that use case, by deploying a more complex configuration of Dagster, which utilizes the CeleryK8sRunLauncher and celery_k8s_job_executor.
Deployment architecture
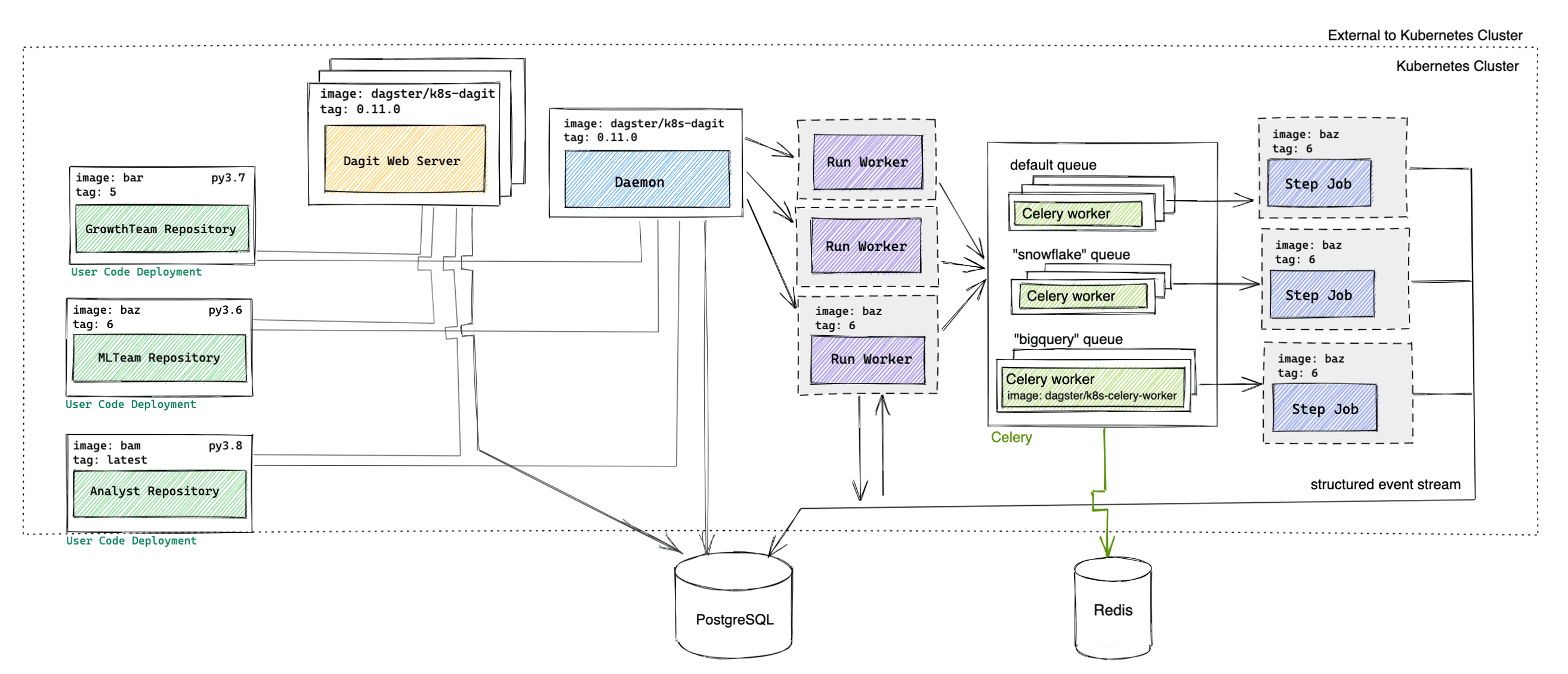
Components
| Component name | Type | Image |
|---|---|---|
| Celery | Deployment | dagster/dagster-celery-k8s (Released weekly) |
| Daemon | Deployment | dagster/dagster-celery-k8s (Released weekly) |
| Dagster webserver | Deployment behind a Service | dagster/dagster-celery-k8s (Released weekly) |
| Database | PostgreSQL | postgres (Optional) |
| Flower (Optional) | Deployment behind a Service | mher/flower |
| Run worker | Job | User-provided or dagster/user-code-example (Released weekly) |
| Step job | Job | User-provided or dagster/user-code-example (Released weekly) |
| User code deployment | Deployment behind a Service | User-provided or dagster/user-code-example (Released weekly) |
The Helm chart can be configured to use this architecture by configuring the runLauncher.type field in your values.yaml file to be CeleryK8sRunLauncher instead of the default K8sRunLauncher. The resulting architecture is similar to the architecture described in the Helm deployment guide, with the following changes:
Celery
Users can configure multiple Celery queues (for example, one celery queue for each resource the user would like to limit) and multiple Celery workers per queue via the runLauncher.config.celeryK8sRunLauncher.workerQueues section of values.yaml.
The Celery workers poll for new Celery tasks and execute each task in order of receipt or priority. The Celery task largely consists of launching an ephemeral Kubernetes step worker to execute that step.
Daemon
The daemon now launches runs using the CeleryK8sRunLauncher.
Run worker
The run worker is still responsible for traversing the execution plan, but now uses the celery_k8s_job_executor to submit steps that are ready to be executed to the corresponding Celery queue (instead of executing the step itself).
All jobs being executed on an instance that uses the CeleryK8sRunLauncher must have the celery_k8s_job_executor set in the executor_def field.
Step worker
The step worker is responsible for executing a single step, writing the structured events to the database. The Celery worker polls for the step worker completion.
Flower
Flower is an optional component that can be useful for monitoring Celery queues and workers.
Walkthrough
We assume that you've followed the initial steps in the previous walkthrough by building your Docker image for your user code, pushing it to a registry, adding the Dagster Helm chart repository, and configuring your Helm User Deployment values. Note that any job that you wish to run in an instance using the CeleryK8sRunLauncher must be using the celery_k8s_job_executor as its executor. The example user code repository includes an example job that uses the celery_k8s_job_executor, called pod_per_op_celery_job.
Configure persistent object storage
We need to configure persistent object storage so that data can be serialized and passed between steps. To run the Dagster User Code example, create a S3 bucket named "dagster-test".
To enable Dagster to connect to S3, provide AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY environment variables via the env, envConfigMaps, or envSecrets fields under dagster-user-deployments in values.yaml or (not recommended) by setting these variables directly in the User Code Deployment image.
Install the Dagster Helm chart with Celery
Install the Helm chart and create a release, with the run launcher configured to use the CeleryK8sRunLauncher. The helm chart checks for this run launcher type and includes Celery infrastructure in your cluster. Below, we've named our release dagster. We use helm upgrade --install to create the release if it does not exist; otherwise, the existing dagster release will be modified:
helm upgrade --install dagster dagster/dagster -f /path/to/values.yaml \
--set runLauncher.type=CeleryK8sRunLauncher \
--set rabbitmq.enabled=true
Helm will launch several pods. You can check the status of the installation with kubectl. If everything worked correctly, you should see output like the following:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
dagster-celery-workers-74886cfbfb-m9cbc 1/1 Running 1 3m42s
dagster-daemon-68c4b8d68d-vvpls 1/1 Running 1 3m42s
dagster-webserver-69974dd75b-5m8gg 1/1 Running 0 3m42s
dagster-k8s-example-user-code-1-88764b4f4-25mbd 1/1 Running 0 3m42s
dagster-postgresql-0 1/1 Running 0 3m42s
dagster-rabbitmq-0 1/1 Running 0 3m42s
Run a job in your deployment
After Helm has successfully installed all the required kubernetes resources, start port forwarding to the webserver pod via:
DAGSTER_WEBSERVER_POD_NAME=$(kubectl get pods --namespace default \
-l "app.kubernetes.io/name=dagster,app.kubernetes.io/instance=dagster,component=webserver" \
-o jsonpath="{.items[0].metadata.name}")
kubectl --namespace default port-forward $DAGSTER_WEBSERVER_POD_NAME 8080:80
Visit http://127.0.0.1:8080, and navigate to the launchpad. Notice how resources.io_manager.config.s3_bucket is set to dagster-test. You can replace this string with any other accessible S3 bucket. Then, click Launch Run.
You can introspect the jobs that were launched with kubectl:
$ kubectl get jobs
NAME COMPLETIONS DURATION AGE
dagster-step-9f5c92d1216f636e0d33877560818840 1/1 5s 12s
dagster-step-a1063317b9aac91f42ca9eacec551b6f 1/1 12s 34s
dagster-run-fb6822e5-bf43-476f-9e6c-6f9896cf3fb8 1/1 37s 37s
dagster-step- entries correspond to step workers and dagster-run- entries correspond to run workers.
Within the Dagster UI, you can watch the job as it executes.
Configuring Celery queues
Users can configure multiple Celery queues (for example, one queue for each resource to be limited) and multiple Celery workers per queue via the runLauncher.config.celeryK8sRunLauncher.workerQueues section of values.yaml.
To use the queues, dagster-celery/queue can be set on op tags.
By default, all ops will be sent to the default Celery queue named dagster.
@dg.op(
tags = {
'dagster-celery/queue': 'snowflake_queue',
}
)
def my_op(context):
context.log.info('running')
Celery priority
Users can set dagster-celery/run_priority on job tags to configure the baseline priority of all ops from that job. To set priority at the op level, users can set dagster-celery/priority on the op tags. When priorities are set on both a job and an op, the sum of both priorities will be used.
@dg.op(
tags = {
'dagster-celery/priority': 2,
}
)
def my_op(context):
context.log.info('running')
@dg.job(
tags = {
'dagster-celery/run_priority': 3,
}
)
def my_job():
my_op()
Configuring an External Message Broker
In a real deployment, users will likely want to set up an external message broker like Redis rather than RabbitMQ, which can be done by configuring rabbitmq and redis sections of values.yaml.
# values.yaml
rabbitmq:
enabled: false
redis:
enabled: true
internal: false
host: 'redisHost'
port: 6379
brokerDbNumber: 0
backendDbNumber: 0
Conclusion
We deployed Dagster, configured with the CeleryK8sRunLauncher, onto a Kubernetes cluster using Helm.