Branch deployments
This feature is only available in Dagster+.
Branch deployments automatically create ephemeral preview deployments of your Dagster code, right in Dagster+. Every time you push to a branch with an open pull or merge request in the Git repository for your Dagster code, Dagster+ will redeploy the code in the branch, allowing you to preview the changes to the branch in real time, without affecting production or overwriting a test environment.
Supported platforms
Branch deployments can be used with any Git or CI provider. However, setup is easiest with the Dagster GitHub Actions or Dagster GitLab CI/CD workflow, as parts of the process are automated. For more information, see Setting up branch deployments.
Change tracking
When a branch deployment is deployed, it compares the asset definitions in the branch deployment with the asset definitions in the main deployment. The Dagster UI will then mark the changed assets, making it easy to identify changes. For more information, see Change tracking in branch deployments.
Branch deployment example
Below is an example branch deployment setup:
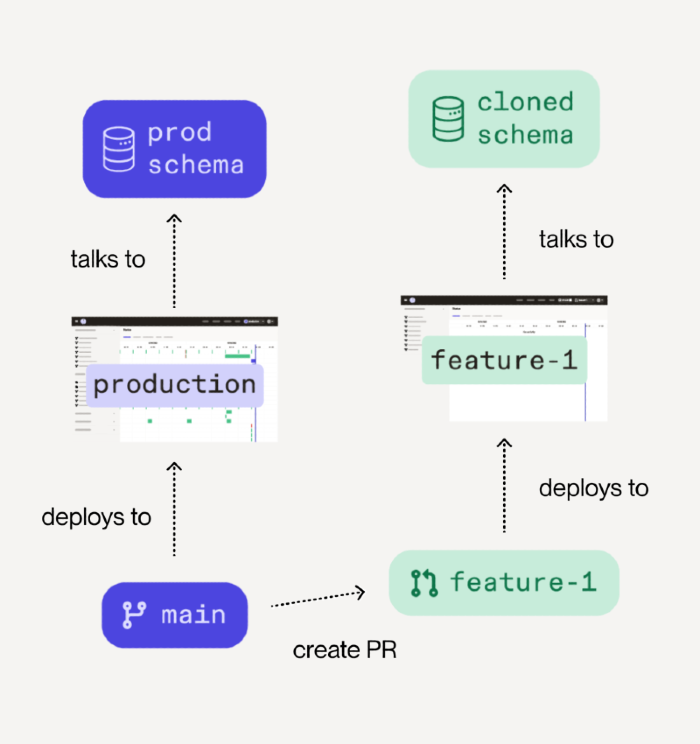
-
In the Git repository, a new branch called
feature-1is created from themainbranch, and a pull request is opened from that branch. -
Dagster+ is notified of the new pull request and creates a branch deployment named
feature-1. The branch deployment functions just like theproductiondeployment of Dagster+, but contains the Dagster code changes from thefeature-1branch.In this example, the
feature-1branch deployment communicates with acloned schemain a database. This is completely separate from theprod schemaassociated with theproductiondeployment. -
For every push to the
feature-1branch, thefeature-1branch deployment in Dagster+ is rebuilt and redeployed.