Executing jobs
You can scaffold jobs from the command line by running dg scaffold defs dagster.job <path/to/job_file.py>. For more information, see the dg CLI docs.
Dagster provides several methods to execute op and asset jobs. This guide explains different ways to do one-off execution of jobs using the Dagster UI, command line, or Python APIs.
You can also launch jobs in other ways:
- Schedules can be used to launch runs on a fixed interval.
- Sensors allow you to launch runs based on external state changes.
Executing a job
- Dagster UI
- Command line
- Python
Using the Dagster UI, you can view, interact, and execute jobs.
To view your job in the UI do one of the following:
- Log into your Dagster+ account
- On the command line, run the
dg devcommand to start the local server, then navigate tohttp://localhost:3000:
Click on the Launchpad tab, then press the Launch Run button to execute the job:
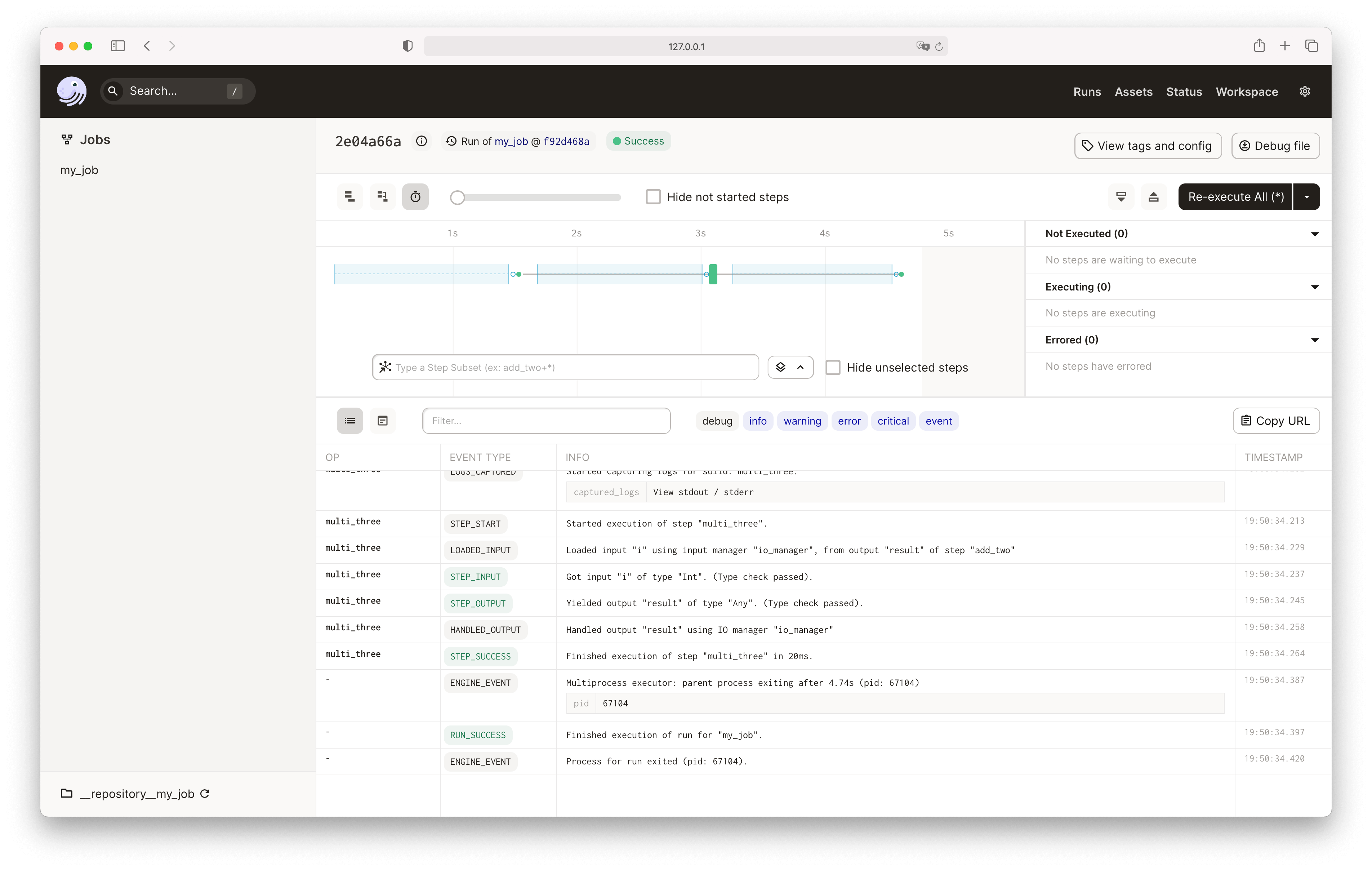
By default, Dagster will run the job using the multiprocess_executor - that means each step in the job runs in its own process, and steps that don't depend on each other can run in parallel.
The Launchpad also offers a configuration editor to let you interactively build up the configuration. For more information, see the run configuration documentation.
The dagster CLI includes the following commands for job execution:
dg launchfor launching runs asynchronously using the run launcher on your instance
To execute your job directly, run:
dg launch --jobs my_job
Dagster includes Python APIs for execution that are useful when writing tests or scripts.
JobDefinition.execute_in_process executes a job and
returns an ExecuteInProcessResult.
if __name__ == "__main__":
result = my_job.execute_in_process()
You can find the full API documentation in Execution API and learn more about the testing use cases in the testing documentation.
Executing job subsets
Dagster supports ways to run a subset of a job, called op selection.
Op selection syntax
To specify op selection, Dagster supports a simple query syntax.
It works as follows:
- A query includes a list of clauses.
- A clause can be an op name, in which case that op is selected.
- A clause can be an op name preceded by
*, in which case that op and all of its ancestors (upstream dependencies) are selected. - A clause can be an op name followed by
*, in which case that op and all of its descendants (downstream dependencies) are selected. - A clause can be an op name followed by any number of
+s, in which case that op and descendants up to that many hops away are selected. - A clause can be an op name preceded by any number of
+s, in which case that op and ancestors up to that many hops away are selected.
Let's take a look at some examples:
| Example | Description |
|---|---|
some_op | Select some_op |
*some_op | Select some_op and all ancestors (upstream dependencies). |
some_op* | Select some_op and all descendants (downstream dependencies). |
*some_op* | Select some_op and all of its ancestors and descendants. |
+some_op | Select some_op and its direct parents. |
some_op+++ | Select some_op and its children, its children's children, and its children's children's children. |
Specifying op selection
Use this selection syntax in the op_selection argument to the JobDefinition.execute_in_process:
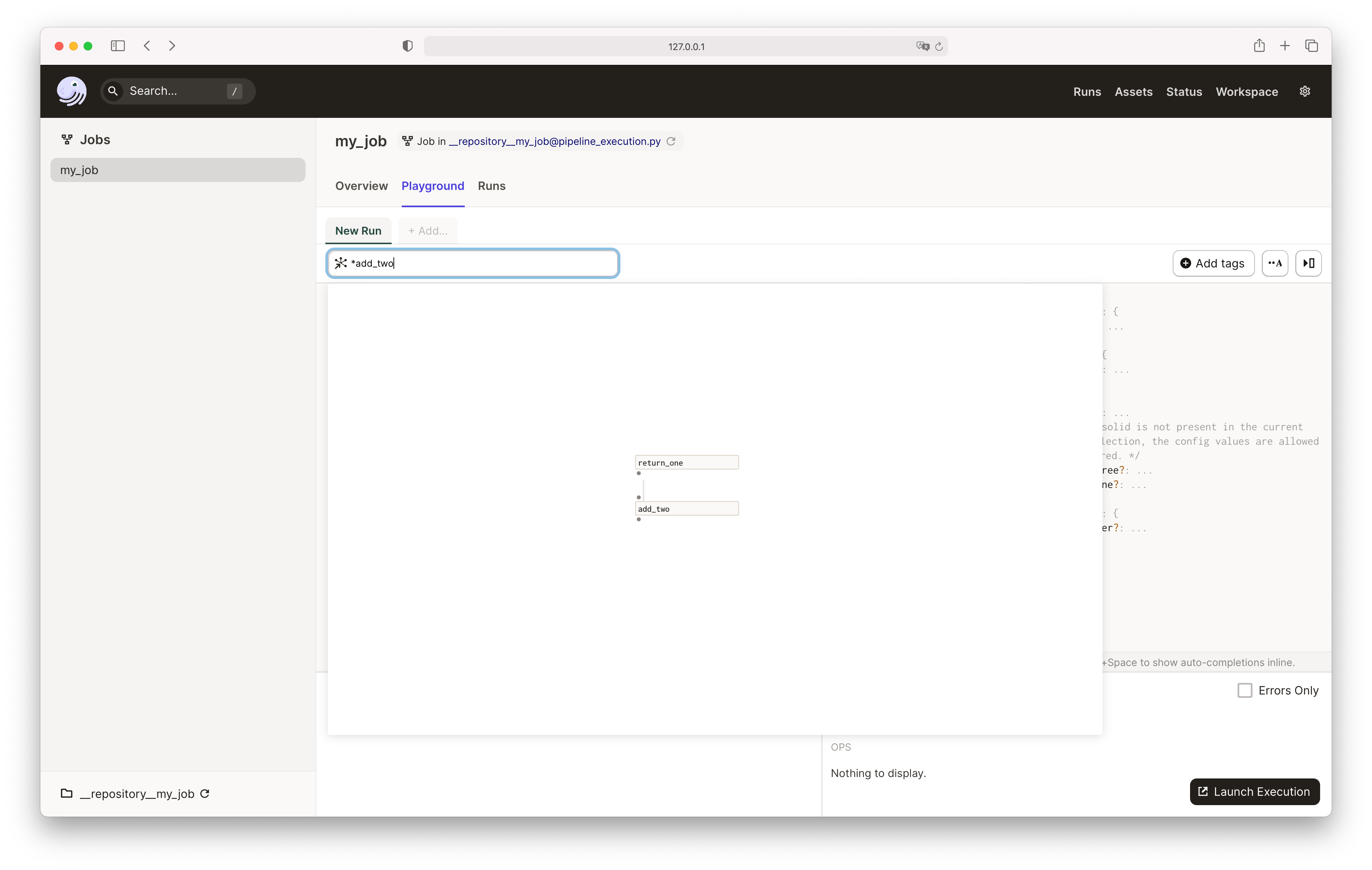
my_job.execute_in_process(op_selection=["*add_two"])
Similarly, you can specify the same op selection in the Dagster UI Launchpad:
Controlling job execution
Each JobDefinition contains an ExecutorDefinition that determines how it will be executed.
This executor_def property can be set to allow for different types of isolation and parallelism, ranging from executing all the ops in the same process to executing each op in its own Kubernetes pod. See Executors for more details.
Default job executor
The default job executor definition defaults to multiprocess execution. It also allows you to toggle between in-process and multiprocess execution via config.
Below is an example of run config as YAML you could provide in the Dagster UI playground to launch an in-process execution.
execution:
config:
in_process:
Additional config options are available for multiprocess execution that can help with performance. This includes limiting the max concurrent subprocesses and controlling how those subprocesses are spawned.
The example below sets the run config directly on the job to explicitly set the max concurrent subprocesses to 4, and change the subprocess start method to use a forkserver.
@dg.job(
config={
"execution": {
"config": {
"multiprocess": {
"start_method": {
"forkserver": {},
},
"max_concurrent": 4,
},
}
}
}
)
def forkserver_job():
multi_three(add_two(return_one()))
Using a forkserver is a great way to reduce per-process overhead during multiprocess execution, but can cause issues with certain libraries. Refer to the Python documentation for more info.
Op concurrency limits
In addition to the max_concurrent limit, you can use tag_concurrency_limits to specify limits on the number of ops with certain tags that can execute at once within a single run.
Limits can be specified for all ops with a certain tag key or key-value pair. If any limit would be exceeded by launching an op, then the op will stay queued. Asset jobs will look at the op_tags field on each asset in the job when checking them for tag concurrency limits.
For example, the following job will execute at most two ops at once with the database tag equal to redshift, while also ensuring that at most four ops execute at once:
@dg.job(
config={
"execution": {
"config": {
"multiprocess": {
"max_concurrent": 4,
"tag_concurrency_limits": [
{
"key": "database",
"value": "redshift",
"limit": 2,
}
],
},
}
}
}
)
def tag_concurrency_job(): ...
These limits are only applied on a per-run basis. You can apply op concurrency limits across multiple runs using the celery_executor or celery_k8s_job_executor.
Refer to the Managing concurrency in data pipelines guide for more info about op concurrency, and how to limit run concurrency.