Dagster Pipes with Databricks (DBFS, classic clusters)
This article covers how to launch Databricks jobs on classic (non-serverless) clusters using DBFS with Dagster Pipes. For more on connecting Databricks with Dagster, see the Databricks integration.
Pipes allows your Databricks jobs to stream logs (including stdout and stderr of the driver process) and events back to Dagster. This does not require a full Dagster environment on Databricks; instead:
- The Databricks environment needs to include
dagster-pipes, a single-file Python package with no dependencies that can be installed from PyPI or easily vendored, and - Databricks jobs must be launched from Dagster
For serverless Databricks compute using Unity Catalog Volumes, see Dagster Pipes with Databricks (serverless compute).
Prerequisites
To run the examples, you'll need to:
- Create a new Dagster project:
uvx create-dagster@latest project <project-name> - Install the necessary Python libraries:
- uv
- pip
Install the required dependencies:
uv add dagster-databricks
Install the required dependencies:
pip install dagster-databricks
-
Refer to the Dagster installation guide for more info. In Databricks, you'll need:
-
A Databricks workspace. If you don't have this, follow the Databricks quickstart to set one up.
-
The following information about your Databricks workspace:
host- The host URL of your Databricks workspace, ex:https://dbc-xxxxxxx-yyyy.cloud.databricks.com/token- A personal access token for the Databricks workspace. Refer to the Databricks API authentication documentation for more info about retrieving these values.
You should set and export the Databricks host and token environment variables in your shell session:
export DATABRICKS_HOST=<your-host-url>
export DATABRICKS_TOKEN=<your-personal-access-token>
-
Step 1: Create an asset computed in Databricks
In this step, you'll create a Dagster asset that, when materialized, opens a Dagster pipes session and launches a Databricks job.
Step 1.1: Define the Dagster asset
You can scaffold assets from the command line by running dg scaffold defs dagster.asset <path/to/asset_file.py>. For more information, see the dg CLI docs.
In your Dagster project, create a file named dagster_databricks_pipes.py and paste in the following code:
import os
import sys
from dagster_databricks import PipesDatabricksClient
import dagster as dg
from databricks.sdk import WorkspaceClient
from databricks.sdk.service import jobs
@dg.asset
def databricks_asset(
context: dg.AssetExecutionContext, pipes_databricks: PipesDatabricksClient
):
task = jobs.SubmitTask.from_dict(
{
# The cluster settings below are somewhat arbitrary. Dagster Pipes is
# not dependent on a specific spark version, node type, or number of
# workers.
"new_cluster": {
"spark_version": "12.2.x-scala2.12",
"node_type_id": "i3.xlarge",
"num_workers": 0,
"cluster_log_conf": {
"dbfs": {"destination": "dbfs:/cluster-logs-dir-noexist"},
},
},
"libraries": [
# Include the latest published version of dagster-pipes on PyPI
# in the task environment
{"pypi": {"package": "dagster-pipes"}},
],
"task_key": "some-key",
"spark_python_task": {
"python_file": "dbfs:/my_python_script.py", # location of target code file
"source": jobs.Source.WORKSPACE,
},
}
)
print("This will be forwarded back to Dagster stdout")
print("This will be forwarded back to Dagster stderr", file=sys.stderr)
extras = {"some_parameter": 100}
return pipes_databricks.run(
task=task,
context=context,
extras=extras,
).get_materialize_result()
Let's review what's happening in this code:
-
Includes a number of imports from Dagster and the Databricks SDK. There are a few that aren't used in this code block, but will be later in this guide.
-
Creates an asset named
databricks_asset. We also:- Provided
AssetExecutionContextas thecontextargument to the asset. This object provides access to system APIs such as resources, config, and logging. We'll come back to this a bit later in this section. - Specified a
PipesDatabricksClientresource for the asset to use. We'll also come back to this later.
- Provided
-
Defines a Databricks
SubmitTaskobject in the asset body. Coverage of all the fields on this object is beyond the scope of this guide, but you can find further information in the Databricks SDK API docs and source code for theSubmitTaskobject.The submitted task must:
- Specify
dagster-pipesas a PyPI dependency. You can include a version pin (e.g.dagster-pipes==1.5.4) if desired. - Use a
spark_python_task. - Specify either
new_cluster(this is the recommended approach) orexisting_cluster_id. Thenew_clusterfield is used in this example.- If
new_clusteris set, then settingnew_cluster.cluster_log_conf.dbfsenables thePipesDatabricksClientto automatically set upPipesDbfsLogReaderobjects forstdoutandstderrof the driver process. These will periodically forward thestdoutandstderrlogs written by Databricks back to Dagster. Note that because Databricks only updates these log files every five minutes, that is the maximum frequency at which Dagster can forward the logs. - If
existing_cluster_idis set,PipesDatabricksClientwon't be able to forwardstdoutandstderrdriver logs to Dagster. Using an existing cluster requires passing an instance ofPipesCliArgsParamsLoadertoopen_dagster_pipesin the Python script which is executed on Databricks. This is because setting environment variables is only possible when creating a new cluster, so we have to use the alternative method of passing Pipes parameters as command-line arguments.
- If
- Specify
-
Defines an
extrasdictionary containing some arbitrary data (some_parameter). This is where you can put various data, e.g. from the Dagster run config, that you want to be available in Databricks. Anything added here must be JSON-serializable. -
Passes the
SubmitTaskobject,AssetExecutionContext, andextrasdictionary to therunmethod ofPipesDatabricksClient. This method synchronously executes the Databricks job specified by theSubmitTaskobject. It slightly modifies the object by injecting some environment variables undernew_cluster.spark_env_varsbefore submitting the object to the Databricks API. -
Returns a
MaterializeResultobject representing the result of execution. This is obtained by callingget_materialize_resulton thePipesClientCompletedInvocationobject returned byrunafter the Databricks job has finished. Execution can take several minutes even for trivial scripts due to Databricks cluster provisioning times.
Step 1.2: Define the Databricks Pipes client and definitions
You can scaffold resources from the command line by running dg scaffold defs dagster.resources <path/to/resources_file.py>. For more information, see the dg CLI docs.
The dagster-databricks library provides a PipesDatabricksClient, which is a pre-built Dagster resource that allows you to quickly get Pipes working with your Databricks workspace.
Add the following to the bottom of dagster_databricks_pipes.py to define the resource and a Definitions object that binds it to the databricks_asset:
import os
from dagster_databricks import PipesDatabricksClient
import dagster as dg
from databricks.sdk import WorkspaceClient
pipes_databricks_resource = PipesDatabricksClient(
client=WorkspaceClient(
host=os.environ["DATABRICKS_HOST"],
token=os.environ["DATABRICKS_TOKEN"],
)
)
@dg.definitions
def resources():
return dg.Definitions(resources={"pipes_databricks": pipes_databricks_resource})
Step 2: Write a script for execution on Databricks
The next step is to write the code that will be executed on Databricks. In the Databricks task specification in Step 1.1, we referenced a file dbfs:/my_python_script.py in the spark_python_task:
"spark_python_task": {
"python_file": "dbfs:/my_python_script.py", # location of target code file
"source": jobs.Source.WORKSPACE,
}
We'll create this script from scratch and upload it to DBFS. You can use the Databricks UI or run a command from a shell to do this. To use the shell method, run:
dbfs cp my_python_script.py dbfs:/my_python_script.py
Let's look at the script itself:
### dbfs:/my_python_script.py
# `dagster_pipes` must be available in the databricks python environment
from dagster_pipes import (
PipesDbfsContextLoader,
PipesDbfsMessageWriter,
open_dagster_pipes,
)
# Sets up communication channels and downloads the context data sent from Dagster.
# Note that while other `context_loader` and `message_writer` settings are
# possible, it is recommended to use `PipesDbfsContextLoader` and
# `PipesDbfsMessageWriter` for Databricks.
with open_dagster_pipes(
context_loader=PipesDbfsContextLoader(),
message_writer=PipesDbfsMessageWriter(),
) as pipes:
# Access the `extras` dict passed when launching the job from Dagster.
some_parameter_value = pipes.get_extra("some_parameter")
# Stream log message back to Dagster
pipes.log.info(f"Using some_parameter value: {some_parameter_value}")
# ... your code that computes and persists the asset
# Stream asset materialization metadata and data version back to Dagster.
# This should be called after you've computed and stored the asset value. We
# omit the asset key here because there is only one asset in scope, but for
# multi-assets you can pass an `asset_key` parameter.
pipes.report_asset_materialization(
metadata={
"some_metric": {"raw_value": some_parameter_value + 1, "type": "int"}
},
data_version="alpha",
)
The metadata format shown above ({"raw_value": value, "type": type}) is part of Dagster Pipes' special syntax for specifying rich Dagster metadata. For a complete reference of all supported metadata types and their formats, see the Dagster Pipes metadata reference.
Before we go any further, let's review what this script does:
-
Imports
PipesDbfsContextLoader,PipesDbfsMessageWriter, andopen_dagster_pipesfromdagster_pipes. ThePipesDbfsContextLoaderandPipesDbfsMessageWriterare DBFS-specific implementations of thePipesContextLoaderandPipesMessageWriter. Refer to the Dagster Pipes details and customization Guide for protocol details.Both objects write temporary files on DBFS for communication between the orchestration and external process. The
PipesDbfsContextLoaderandPipesDbfsMessageWritermatch a correspondingPipesDbfsContextInjectorandPipesDbfsMessageReaderon the orchestration end, which are instantiated inside thePipesDatabricksClient. -
Passes the context loader and message writer to the
open_dagster_pipescontext manager, which yields an instance ofPipesContextcalledpipes. Note that when usingexisting_cluster_id, you must also importPipesCliArgsParamsLoaderand pass an instance of it toopen_dagster_pipesas theparams_loaderparameter.Inside the body of the context manager are various calls against
pipesto retrieve an extra, log, and report an asset materialization. All of these calls will use the DBFS temporary file-based communications channels established byPipesDbfsContextLoaderandPipesDbfsMessageWriter. To see the full range of what you can do with thePipesContext, see the API docs or the general Pipes guide.
At this point you can execute the rest of your Databricks code as normal, invoking various PipesContext APIs as needed.
Existing codebases
For illustrative purposes, we've created a Python script from scratch. However, you may want to apply Pipes to an existing codebase.
One approach that can be useful is to wrap the open_dagster_pipes context manager around an existing main function or entry point. You can either pass the PipesContext down through your business logic, or simply report an asset materialization after your business logic is done:
from dagster_pipes import (
PipesDbfsContextLoader,
PipesDbfsMessageWriter,
open_dagster_pipes,
)
# ... existing code
Step 3: Run the Databricks job from the Dagster UI
In this step, you'll run the Databricks job you created in Step 1.2 from the Dagster UI.
-
In a new command line session, run the following to start the UI:
dg dev -
Navigate to localhost:3000, where you should see the UI:
-
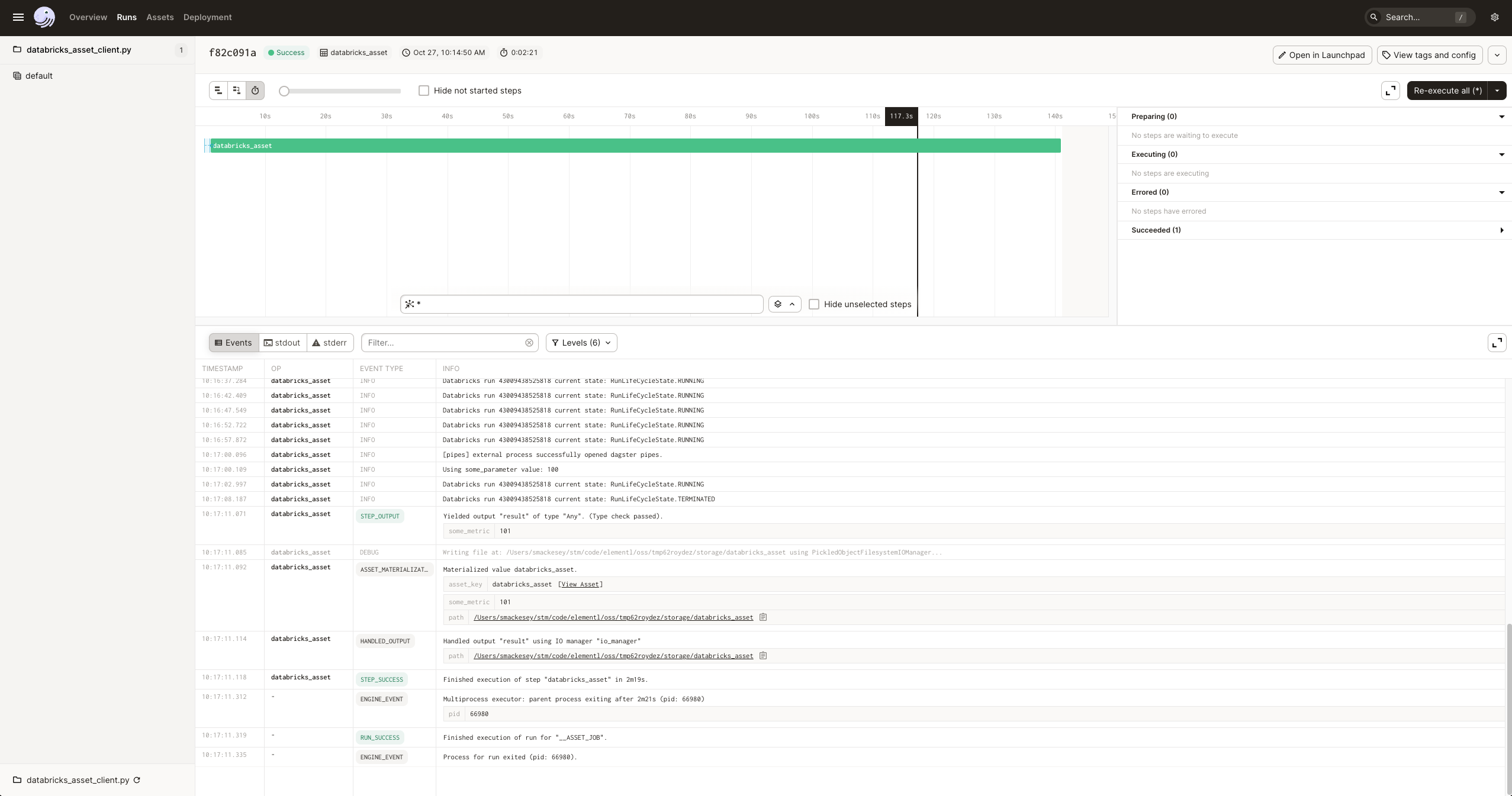
Click Materialize near the top right corner of the page, then click View on the Launched Run popup. Wait for the run to complete, and the event log should look like this:
Advanced: Customization using open_pipes_session
The PipesDatabricksClient is a high-level API that doesn't cover all use cases. If you have existing code to launch/poll the job you do not want to change, you want to stream back materializations as they occur, or you just want more control than is permitted by PipesDatabricksClient, you can use open_pipes_session instead of PipesDatabricksClient.
To use open_pipes_session:
- Your Databricks job be launched within the scope of the
open_pipes_sessioncontext manager; and - Your job is launched on a cluster containing the environment variables available on the yielded
pipes_session
While your Databricks code is running, any calls to report_asset_materialization in the external script are streamed back to Dagster, causing a MaterializeResult object to be buffered on the pipes_session. You can either:
- Leave these objects buffered until execution is complete (Option 1 in below example code), or
- Stream them to Dagster machinery during execution by calling
yield pipes_session.get_results()(Option 2)
With either option, once the open_pipes_session block closes, you must call yield pipes_session.get_results() to yield any remaining buffered results, since we cannot guarantee that all communications from Databricks have been processed until the open_pipes_session block closes.
import os
import sys
from dagster_databricks import PipesDbfsContextInjector, PipesDbfsMessageReader
from dagster_databricks.pipes import PipesDbfsLogReader
from dagster import AssetExecutionContext, asset, open_pipes_session
from databricks.sdk import WorkspaceClient
@asset
def databricks_asset(context: AssetExecutionContext):
client = WorkspaceClient(
host=os.environ["DATABRICKS_HOST"],
token=os.environ["DATABRICKS_TOKEN"],
)
# Arbitrary json-serializable data you want access to from the `PipesContext`
# in the Databricks runtime. Assume `sample_rate` is a parameter used by
# the target job's business logic.
extras = {"sample_rate": 1.0}
# Sets up Pipes communications channels
with open_pipes_session(
context=context,
extras=extras,
context_injector=PipesDbfsContextInjector(client=client),
message_reader=PipesDbfsMessageReader(
client=client,
# These log readers are optional. If you provide them, then you must set the
# `new_cluster.cluster_log_conf.dbfs.destination` field in the job you submit to a valid
# DBFS path. This will configure Databricks to write stdout/stderr to the specified
# location every 5 minutes. Dagster will poll this location and forward the
# stdout/stderr logs every time they are updated to the orchestration process
# stdout/stderr.
log_readers=[
PipesDbfsLogReader(
client=client, remote_log_name="stdout", target_stream=sys.stdout
),
PipesDbfsLogReader(
client=client, remote_log_name="stderr", target_stream=sys.stderr
),
],
),
) as pipes_session:
##### Option (1)
# NON-STREAMING. Just pass the necessary environment variables down.
# During execution, all reported materializations are buffered on the
# `pipes_session`. Yield them all after Databricks execution is finished.
# Dict[str, str] with environment variables containing Pipes comms info.
env_vars = pipes_session.get_bootstrap_env_vars()
# Some function that handles launching/monitoring of the Databricks job.
# It must ensure that the `env_vars` are set on the executing cluster.
custom_databricks_launch_code(env_vars)
##### Option (2)
# STREAMING. Pass `pipes_session` down. During execution, you can yield any
# asset materializations that have been reported by calling `
# pipes_session.get_results()` as often as you like. `get_results` returns
# an iterator that your custom code can `yield from` to forward the
# results back to the materialize function. Note you will need to extract
# the env vars by calling `pipes_session.get_pipes_bootstrap_env_vars()`,
# and launch the Databricks job in the same way as with (1).
# The function should return an `Iterator[MaterializeResult]`.
yield from custom_databricks_launch_code(pipes_session)
# With either option (1) or (2), this is required to yield any remaining
# buffered results.
yield from pipes_session.get_results()