Schedules#
A schedule is a Dagster definition that is used to execute a job at a fixed interval. Each time at which a schedule is evaluated is called a tick. The schedule definition can generate run configuration for the job on each tick.
Each schedule:
- Targets a single job
- Optionally defines a function that returns either:
- One or more
RunRequestobjects. Each run request launches a run. - An optional
SkipReason, which specifies a message which describes why no runs were requested
- One or more
Dagster includes a scheduler, which runs as part of the dagster-daemon process. Once you have defined a schedule, see the dagster-daemon page for instructions on how to run the daemon in order to execute your schedules.
Relevant APIs#
| Name | Description |
|---|---|
@schedule | Decorator that defines a schedule that executes according to a given cron schedule. |
ScheduleDefinition | Class for schedules. |
build_schedule_from_partitioned_job | A function that constructs a schedule whose interval matches the partitioning of a partitioned job. |
ScheduleEvaluationContext | The context passed to the schedule definition execution function |
build_schedule_context | A function that constructs a ScheduleEvaluationContext, typically used for testing. |
Defining schedules#
You define a schedule by constructing a ScheduleDefinition. In this section:
- Basic schedules
- Schedules that provide custom run config and tags
- Schedules from partitioned assets and jobs
- Customizing execution times, including timezones and accounting for Daylight Savings Time
Basic schedules#
Here's a simple schedule that runs a job every day, at midnight:
@job def my_job(): ... basic_schedule = ScheduleDefinition(job=my_job, cron_schedule="0 0 * * *")
The cron_schedule argument accepts standard cron expressions. It also accepts "@hourly", "@daily", "@weekly", and "@monthly" if your croniter dependency's version is >= 1.0.12.
To run schedules for assets, you can build a job that materializes assets and construct a ScheduleDefinition:
from dagster import AssetSelection, define_asset_job asset_job = define_asset_job("asset_job", AssetSelection.groups("some_asset_group")) basic_schedule = ScheduleDefinition(job=asset_job, cron_schedule="0 0 * * *")
Schedules that provide custom run config and tags#
If you want to vary the behavior of your job based on the time it's scheduled to run, you can use the @schedule decorator, which decorates a function that returns run config based on a provided ScheduleEvaluationContext:
@op(config_schema={"scheduled_date": str}) def configurable_op(context: OpExecutionContext): context.log.info(context.op_config["scheduled_date"]) @job def configurable_job(): configurable_op() @schedule(job=configurable_job, cron_schedule="0 0 * * *") def configurable_job_schedule(context: ScheduleEvaluationContext): scheduled_date = context.scheduled_execution_time.strftime("%Y-%m-%d") return RunRequest( run_key=None, run_config={ "ops": {"configurable_op": {"config": {"scheduled_date": scheduled_date}}} }, tags={"date": scheduled_date}, )
If you don't need access to the context parameter, you can omit it from the decorated function.
Schedules from partitioned assets and jobs#
Time partitioned jobs and assets#
When you have a partitioned job that's partitioned by time, you can use the build_schedule_from_partitioned_job function to construct a schedule for it whose interval matches the spacing of partitions in your job. For example, if you have a daily partitioned job that fills in a date partition of a table each time it runs, you likely want to run that job every day.
Having defined a date-partitioned job, you can construct a schedule for it using build_schedule_from_partitioned_job. For example:
from dagster import build_schedule_from_partitioned_job, job @job(config=my_partitioned_config) def do_stuff_partitioned(): ... do_stuff_partitioned_schedule = build_schedule_from_partitioned_job( do_stuff_partitioned, )
The Partitioning assets documentation includes an example of a date-partitioned asset. You can define a schedule similarly using build_schedule_from_partitioned_job:
from dagster import ( asset, build_schedule_from_partitioned_job, define_asset_job, HourlyPartitionsDefinition, ) @asset(partitions_def=HourlyPartitionsDefinition(start_date="2020-01-01-00:00")) def hourly_asset(): ... partitioned_asset_job = define_asset_job("partitioned_job", selection=[hourly_asset]) asset_partitioned_schedule = build_schedule_from_partitioned_job( partitioned_asset_job, )
Each schedule tick of a partitioned job fills in the latest partition in the partition set that exists as of the tick time. Note that this implies that when the schedule submits a run on a particular day, it will typically be for the partition whose key corresponds to the previous day. For example, the schedule will fill in the 2020-04-01 partition on 2020-04-02. That's because each partition corresponds to a time window. The key of the partition is the start of the time window, but the partition isn't included in the list until its time window has completed. Waiting until the time window has finished before Kicking off a run means the run can process data from within that entire time window.
However, you can use the end_offset parameter of @daily_partitioned_config to change which partition is the most recent partition that is filled in at each schedule tick. Setting end_offset to 1 will extend the partitions forward so that the schedule tick that runs on day N will fill in day N's partition instead of day N-1, and setting end_offset to a negative number will cause the schedule to fill in earlier days' partitions. In general, setting end_offset to X will cause the partition that runs on day N to fill in the partition for day N - 1 + X. The same holds true for hourly, weekly, and monthly partitioned jobs, for their respective partition sizes.
You can use the minute_of_hour, hour_of_day, day_of_week, and day_of_month parameters of build_schedule_from_partitioned_job to control the timing of the schedule. For example, if you have a job that's partitioned by date, and you set minute_of_hour to 30 and hour_of_day to 1, the schedule would submit the run for partition 2020-04-01 at 1:30 AM on 2020-04-02.
Static partitioned jobs#
You can also create a schedule for a static partition. The Partitioned Jobs concepts page also includes an example of how to define a static partitioned job. To define a schedule for a static partitioned job, we will construct a schedule from scratch, rather than using a helper function like build_schedule_from_partitioned_job this will allow more flexibility in determining which partitions should be run by the schedule.
For example, if we have the continents static partitioned job from the Partitioned Jobs concept page
from dagster import Config, OpExecutionContext, job, op, static_partitioned_config CONTINENTS = [ "Africa", "Antarctica", "Asia", "Europe", "North America", "Oceania", "South America", ] @static_partitioned_config(partition_keys=CONTINENTS) def continent_config(partition_key: str): return {"ops": {"continent_op": {"config": {"continent_name": partition_key}}}} class ContinentOpConfig(Config): continent_name: str @op def continent_op(context: OpExecutionContext, config: ContinentOpConfig): context.log.info(config.continent_name) @job(config=continent_config) def continent_job(): continent_op()
We can write a schedule that will run this partition:
from dagster import schedule, RunRequest @schedule(cron_schedule="0 0 * * *", job=continent_job) def continent_schedule(): for c in CONTINENTS: yield RunRequest(run_key=c, partition_key=c)
Or a schedule that will run a subselection of the partition:
@schedule(cron_schedule="0 0 * * *", job=continent_job) def antarctica_schedule(): return RunRequest(partition_key="Antarctica")
Customizing execution times#
Customizing the executing timezone#
You can customize the timezone in which your schedule executes by setting the execution_timezone parameter on your schedule to any tz timezone. Schedules with no timezone set run in UTC.
For example, the following schedule executes daily at 9AM in US/Pacific time:
my_timezone_schedule = ScheduleDefinition( job=my_job, cron_schedule="0 9 * * *", execution_timezone="US/Pacific" )
The @schedule decorator accepts the same argument. Schedules from partitioned jobs execute in the timezone defined on the partitioned config.
Execution time and Daylight Savings Time#
Because of Daylight Savings Time transitions, it's possible to specify an execution time that does not exist for every scheduled interval. For example, say you have a daily schedule with an execution time of 2:30 AM in the US/Eastern timezone. On 2019/03/10, the time jumps from 2:00 AM to 3:00 AM when Daylight Savings Time begins. Therefore, the time of 2:30 AM did not exist for the day.
If you specify such an execution time, Dagster runs your schedule at the next time that exists. In the previous example, the schedule would run at 3:00 AM.
It's also possible to specify an execution time that exists twice on one day every year. For example, on 2019/11/03 in US/Eastern time, the hour from 1:00 AM to 2:00 AM repeats, so a daily schedule running at 1:30 AM has two possible times in which it could execute. In this case, Dagster will execute your schedule at the latter of the two possible times.
Hourly schedules will be unaffected by daylight savings time transitions - the schedule will continue to run exactly once every hour, even as the timezone changes. In the example above where the hour from 1:00 AM to 2:00 AM repeats, an hourly schedule running at 30 minutes past the hour would run at 12:30 AM, both instances of 1:30 AM, and then proceed normally from 2:30 AM on.
Using resources in schedules#
Dagster's resources system can be used with schedules to make it easier to interact with external systems or to make components of a schedule easier to plug in for testing purposes.
To specify resource dependencies, annotate the resource as a parameter to the schedule's function. Resources are provided by attaching them to your Definitions call.
Here, a resource is provided that helps a schedule generate a date string:
from dagster import ( schedule, ScheduleEvaluationContext, ConfigurableResource, job, RunRequest, RunConfig, Definitions, ) from datetime import datetime from typing import List class DateFormatter(ConfigurableResource): format: str def strftime(self, dt: datetime) -> str: return dt.strftime(self.format) @job def process_data(): ... @schedule(job=process_data, cron_schedule="* * * * *") def process_data_schedule( context: ScheduleEvaluationContext, date_formatter: DateFormatter, ): formatted_date = date_formatter.strftime(context.scheduled_execution_time) return RunRequest( run_key=None, tags={"date": formatted_date}, ) defs = Definitions( jobs=[process_data], schedules=[process_data_schedule], resources={"date_formatter": DateFormatter(format="%Y-%m-%d")}, )
For more information on resources, refer to the Resources documentation. To see how to test schedules with resources, refer to the section on Testing schedules with resources.
Running the scheduler#
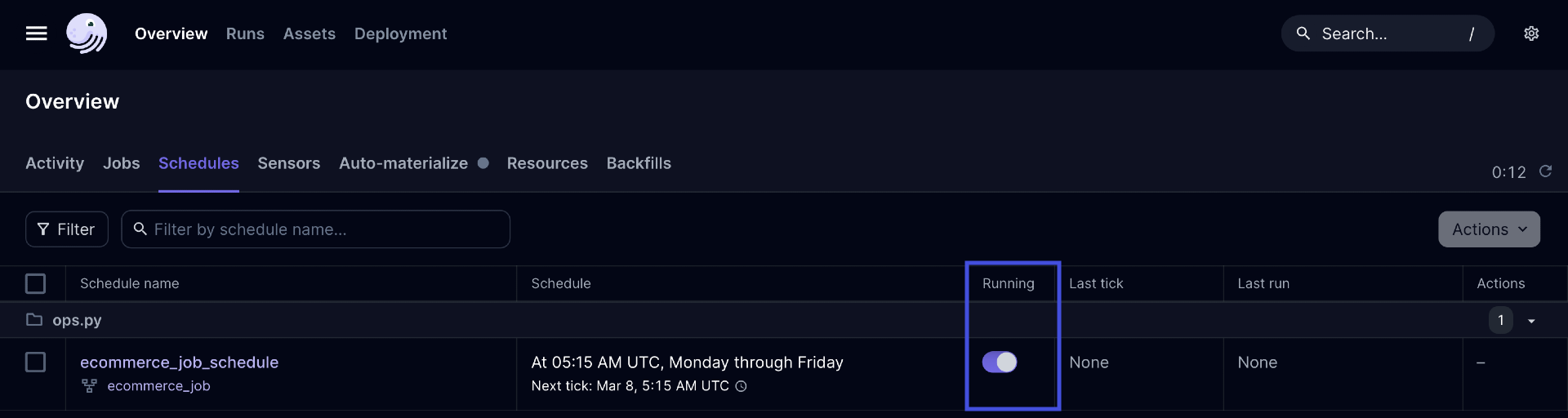
Schedules must be started for them to run. Schedules can be started and stopped:
In the Dagster UI using the Schedules tab:
Using the CLI:
dagster schedule start dagster schedule stopIn code by setting the schedule's default status to
DefaultScheduleStatus.RUNNING:my_running_schedule = ScheduleDefinition( job=my_job, cron_schedule="0 9 * * *", default_status=DefaultScheduleStatus.RUNNING )
If you manually start or stop a schedule in the UI, that overrides any default status set in code.
Once the schedule is started, the schedule will begin executing immediately if you're running the dagster-daemon process as part of your deployment. Refer to the Troubleshooting section if your schedule has been started but isn't submitting runs.
Logging in schedules#
Any schedule can emit log messages during its evaluation function:
@schedule(job=my_job, cron_schedule="* * * * *") def logs_then_skips(context): context.log.info("Logging from a schedule!") return SkipReason("Nothing to do")
These logs can be viewed when inspecting a tick in the tick history view on the corresponding schedule page.
Testing schedules#
Via the Dagster UI#
In the UI, you can manually trigger a test evaluation of a schedule using a mock evaluation time and view the results.
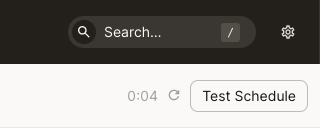
On the overview page for a particular schedule, there is a Test schedule button. Clicking this button will perform a test evaluation of your schedule for a provided mock evaluation time, and show you the results of that evaluation.
Click Overview > Schedules.
Click the schedule you want to test.
Click the Test Schedule button, located near the top right corner of the page:
You'll be prompted to select a mock schedule evaluation time. As schedules are defined on a cadence, the evaluation times provided in the dropdown are past and future times along that cadence.
For example, let's say you're testing a schedule with a cadence of
"Every day at X time". In the dropdown, you'd see five evaluation times in the future and five evaluation times in the past along that cadence.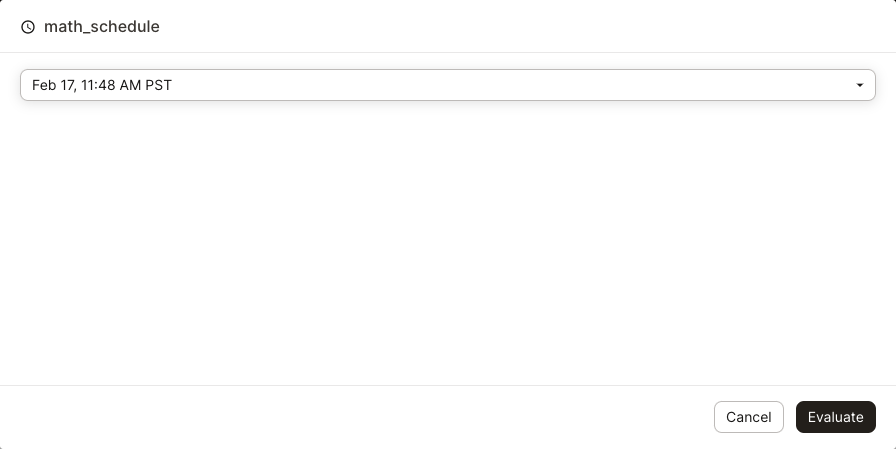
After selecting an evaluation time, click the Evaluate button. A window containing the result of the evaluation will display:
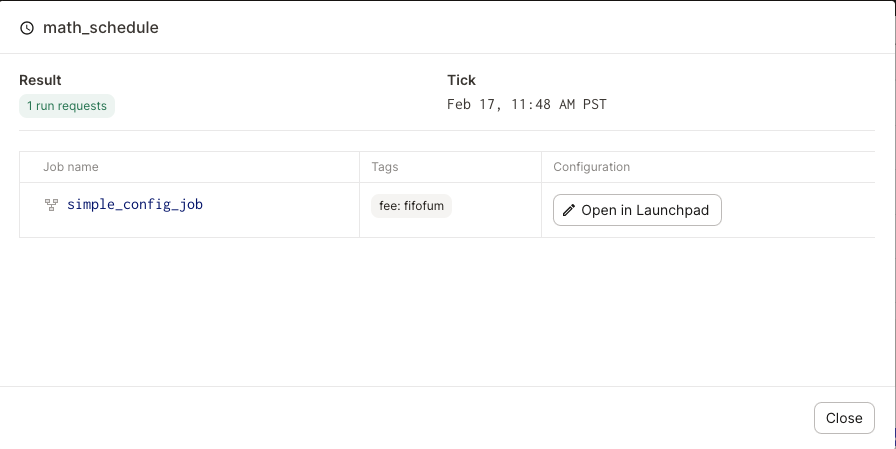
If the evaluation was successful and a run request was produced, you can open the launchpad pre-scaffolded with the config corresponding to that run request.
Troubleshooting#
Try these steps if you're trying to run a schedule and are running into problems:
- Verify the schedule is included as a definition
- Verify the schedule has been started
- Verify schedule interval configuration
- Verify dagster-daemon setup
Verify the schedule is included as a definition#
First, verify that the schedule has been included in a Definitions object. This ensures that the schedule is detectable and loadable by Dagster tools like the UI and CLI:
defs = Definitions( assets=[asset_1, asset_2], jobs=[job_1], schedules=[all_assets_job_schedule], )
Refer to the Code locations documentation for more info.
Verify that the schedule has been started#
Next, using the UI, verify the schedule has been started:
Open the left sidenav and locate the job attached to the schedule. Schedules that have been started will have a green clock icon next to them:
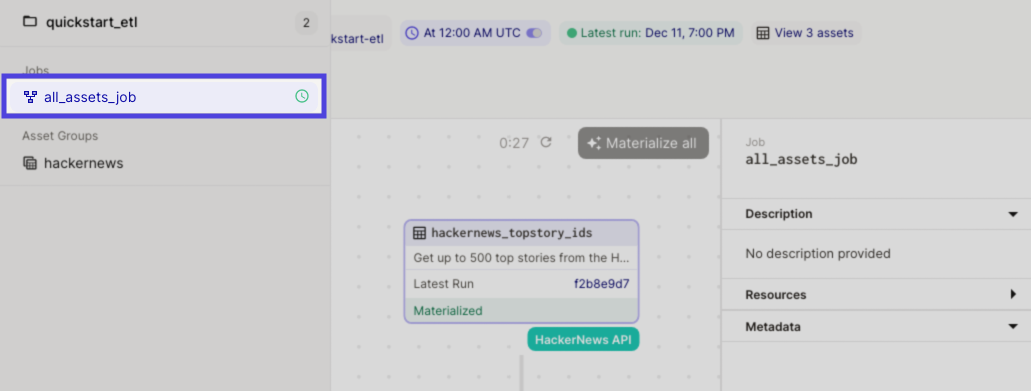
If the schedule appears in the list but doesn't have the green clock icon, click the schedule. On the page that displays, use the toggle at the top of the page to mark it as running:
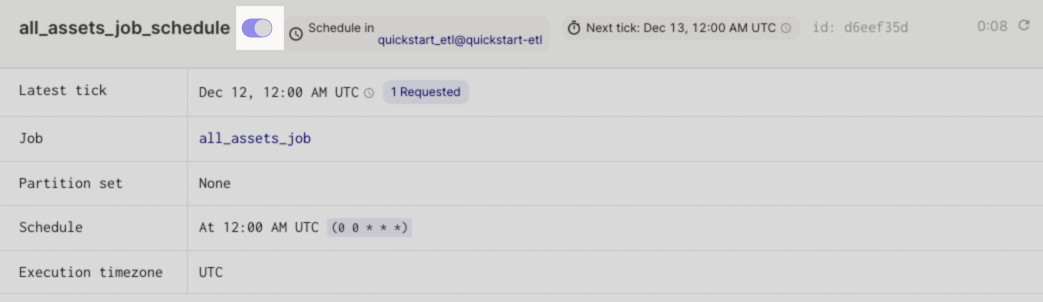
Next, verify that the UI has loaded the latest version of your schedule code:
Click Deployment in the top navigation.
In the Code locations tab, click Reload (local webserver) or Redeploy (Dagster+).
If the webserver is unable to load the code location - for example, due to a syntax error - an error message with additional info will display in the left UI sidenav.
If the code location is loaded successfully but the schedule doesn't appear in the list of schedules, verify that the schedule is included in a
Definitionsobject.
Verify schedule interval configuration#
Clicking the schedule in the left sidenav in the UI opens the Schedule details page for the schedule.
If the schedule is running, a Next tick will display near the top of the page. This indicates when the schedule is next expected to run:
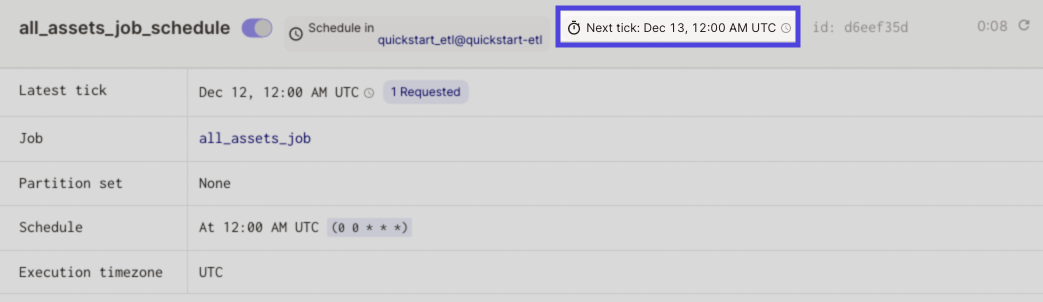
Verify that the time is what you expect, including the timezone.
Verify dagster-daemon setup#
If the schedule interval is correctly configured but runs aren't being created, it's possible that the dagster-daemon process isn't working correctly. If you haven't set up a Dagster daemon yet, refer to the Deployment guides for more info.
First, check that the daemon is running:
- In the UI, click Deployment in the top navigation.
- Click the Daemons tab.
- Locate the Scheduler row.
The daemon process periodically sends out a hearbeat from the scheduler. If the scheduler daemon has a status of Not running, this indicates that there's an issue with your daemon deployment. If the daemon ran into an error that resulted in an exception, this error will often display in this tab.
If there isn't a clear error on this page or if the daemon should be sending heartbeans but isn't, move on to step two.
Next, check the logs from the daemon process. The steps to do this will depend on your deployment - for example, if you're using Kubernetes, you'll need to get the logs from the pod that's running the daemon. You should be able to search those logs for the name of your schedule (or
SchedulerDaemonto see all logs associated with the scheduler) to gain an understanding of what's going wrong.If the daemon output contains error indicating the schedule couldn't be found, verify that the daemon is using the same
workspace.yamlfile as the webserver. The daemon does not need to restart in order to pick up changes to theworkspace.yamlfile. Refer to the Workspace files documentation for more info.If the logs don't indicate the cause of the issue, move on to step three.
Lastly, double-check your schedule code:
- In the UI, open the schedule's Schedule details page by clicking the schedule in the left sidenav.
- On this page, locate the latest tick for the schedule.
If there was an error trying to submit runs for the schedule, a red Failure badge should display in the Status column. Click the badge to display an error and stack trace describing the execution failure.
Still stuck? If these steps didn't resolve the issue, reach out in Slack or file an issue on GitHub.
See it in action#
For more examples of schedules, check out the following in our Hacker News example: