Branch Deployments in Dagster Cloud#
Dagster Cloud provides out-of-the-box support for Continuous Integration (CI) with Branch Deployments.
Branch Deployments automatically create staging environments of your Dagster code, right in Dagster Cloud. For every push to a branch in your git repository, Dagster Cloud will create a unique deployment, allowing you to preview the changes in the branch in real-time.
Understanding Branch Deployments#
Overview#
Think of a branch deployment as a branch of your data platform, one where you can preview changes without impacting production or overwriting a testing environment.
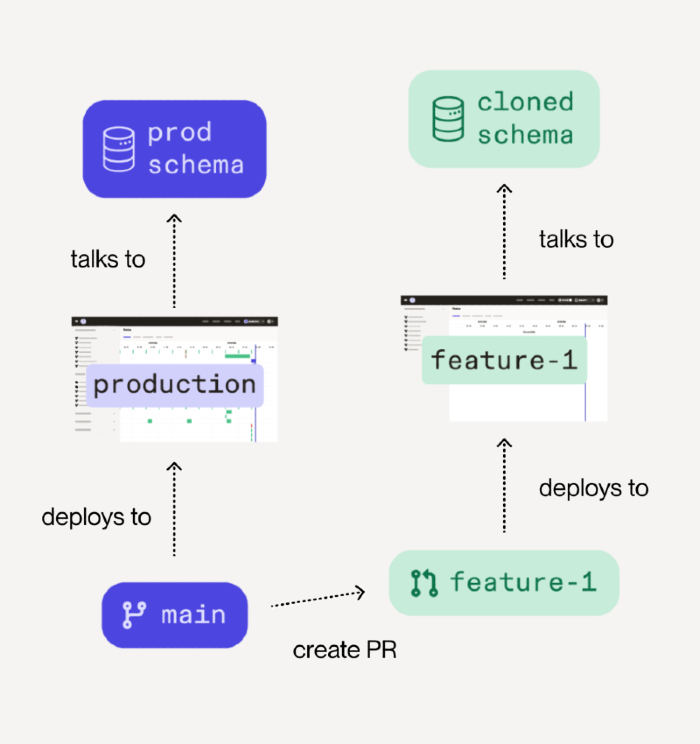
Let's take a closer look:
In your git repository, a new branch is created off of
main. In the example above, this branch is namedfeature-1.Dagster Cloud is notified of the push and creates a branch deployment named
feature-1. The branch deployment functions just like yourproductiondeployment of Dagster Cloud, but contains the Dagster code changes from thefeature-1branch.In this example, the
feature-1branch deployment 'talks' to acloned schemain a database. This is completely separate from theprod schemaassociated with theproductiondeployment.For every push to the
feature-1branch, thefeature-1branch deployment in Dagster Cloud is rebuilt and redeployed.
Benefits#
Now that you know how Branch Deployments work, why should you use them?
- Improved collaboration. Branch Deployments make it easy for everyone on your team to stay in the loop on the latest Dagster changes.
- Reduced development cycle. Quickly test and iterate on your changes without impacting production or overwriting a testing environment.
Requirements#
To use Branch Deployments, you'll need a Dagster Cloud account.
Supported platforms#
Branch Deployments can be used with any git or CI provider. However, setup is easiest with the Dagster GitHub app or Dagster Gitlab app as parts of the process are automated. Refer to the Setting up Branch Deployments section for more info.
Limitations#
Branch Deployments aren't currently supported for use in Dagster Open Source.
Output handling#
Output created from a branch deployment - such as a database, table, etc. - won't be automatically removed from storage once a branch is merged or closed. Refer to the Best practices section for info on how to handle this.
Managing Branch Deployments#
Setting up Branch Deployments#
There are currently two ways to set up Branch Deployments for Dagster Cloud. In the table below:
- Platform - The name of the git/CI platform, which is also a link to a setup guide
- How it works - Summary of how Branch Deployments work with the platform
- May be a good fit if... - A high-level summary of when the platform may be a good fit
| Platform | How it works | May be a good fit if... |
|---|---|---|
| GitHub | GitHub Actions |
|
| Gitlab | Gitlab CI/CD |
|
| Other git/CI platform | dagster-cloud CLI |
|
Accessing a branch deployment#
Once configured, branch deployments can be accessed:
Every pull request in the repository contains a View in Cloud link:
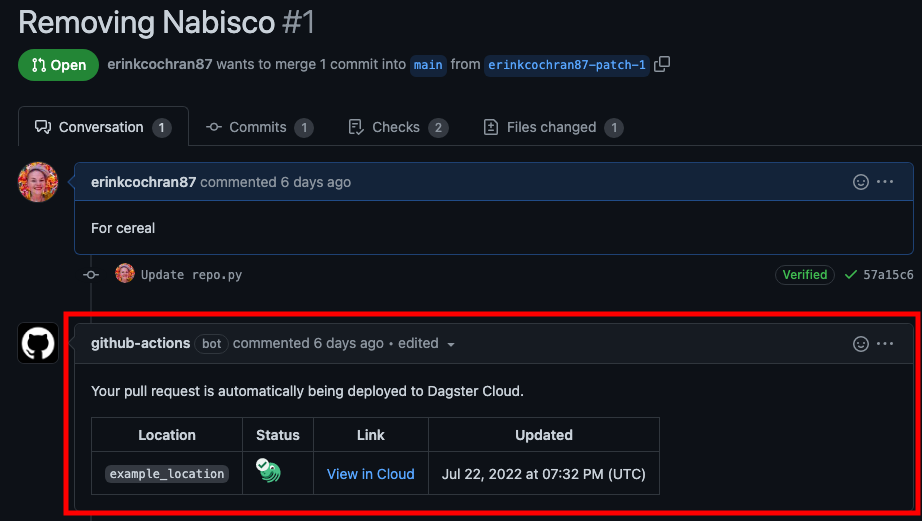
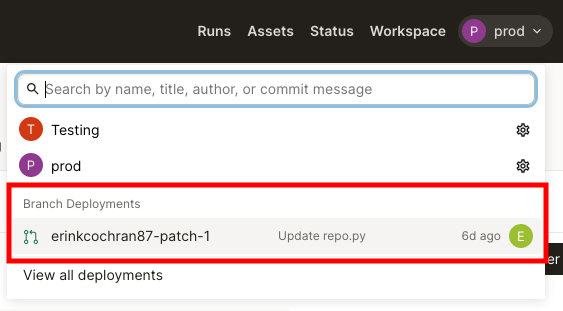
Clicking the link will open a branch deployment - or a preview of the changes - in Dagster Cloud.
Best practices#
To ensure the best experience when using Branch Deployments, we recommend:
Configuring jobs based on environment. Dagster automatically sets environment variables containing deployment metadata, allowing you to parameterize jobs based on the executing environment. Use these variables in your jobs to configure things like connection credentials, databases, and so on. This practice will allow you to use Branch Deployments without impacting production data.
Creating jobs to automate output cleanup. As Branch Deployments don't automatically remove the output they create, you may want to create an additional Dagster job to perform the cleanup.
Want some help with implementation? Check out the Testing against production with Dagster Cloud Branch Deployments guide for a step-by-step look at implementing these best practices in your data pipelines.