I/O managers#
I/O managers are user-provided objects that store asset and op outputs and load them as inputs to downstream assets and ops. They can be a powerful tool that reduces boilerplate code and easily changes where your data is stored.
Functions decorated by @asset, @multi_asset, and @op can return values that are written to persistent storage. Downstream assets and ops can have parameters that load the values from persistent storage. IOManagers let the user control how this data is stored and how it's loaded in downstream ops and assets. For @asset and @multi_asset, the I/O manager effectively determines where the physical asset lives.
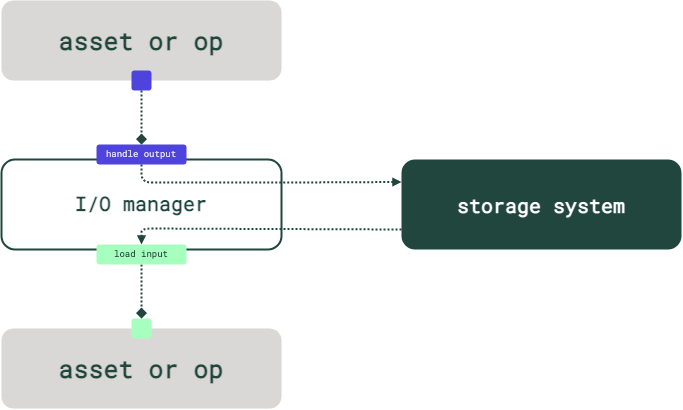
The I/O manager APIs make it easy to separate code that's responsible for logical data transformation from code that's responsible for reading and writing the results. Software-defined Assets and ops can focus on business logic, while I/O managers handle I/O. This separation makes it easier to test the business logic and run it in different environments.
For non-asset jobs with inputs that aren't connected to upstream outputs, see the Unconnected Inputs overview.
Basics#
- When to use I/O managers
- Outputs and downstream inputs
- Built-in I/O managers
- I/O managers are resources
When to use I/O managers#
If you find yourself writing the same code at the start and end of each asset or op to load and store data, you may want to consider factoring that code into an I/O manager. They can be useful in situations where:
- Many assets are stored in the same location and follow a consistent set of rules to determine the storage path
- Assets should be stored differently in local, staging, and production environments
- Asset functions load the upstream dependencies into memory to do the computation
However, I/O managers are not required, nor are they the best option in all scenarios. For example, an asset that executes a Snowflake query to create a new table based on the data of another table. This asset would depend on the existing table, but doesn't need to load that table in memory in order to execute the query:
@asset(deps=[orders]) def returns(): conn = get_snowflake_connection() conn.execute( "CREATE TABLE returns AS SELECT * from orders WHERE status = 'RETURNED'" )
Other reasons you may not want to use I/O managers:
- You want to run a SQL query that creates or updates a table in a database (the above example).
- Your pipeline manages I/O on its own by using other libraries/tools that write to storage.
- You have unique and custom storage requirements for each asset.
- Your assets won't fit in memory (for example, a database table with billions of rows).
- You have an existing pipeline that manages its own I/O and want to run it with Dagster with minimal code changes.
- You simply prefer to have the reading and writing code explicitly defined in each asset.
As a general rule, if your pipeline becomes more complicated in order to use I/O managers, or you find yourself getting confused when implementing I/O managers, it's likely that you are in a situation where I/O managers are not a good fit. In these cases you should use deps to define dependencies.
Outputs and downstream inputs#
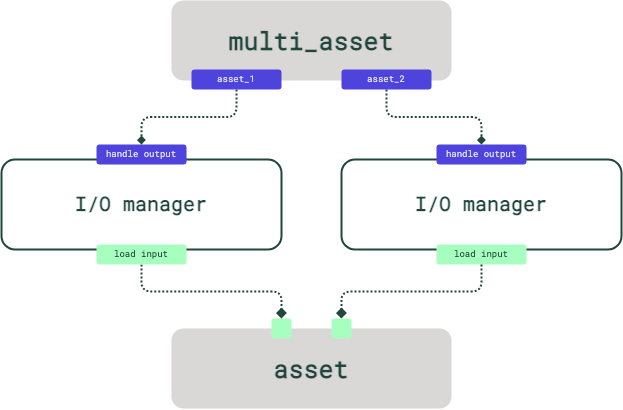
IOManagers are user-provided objects that are responsible for storing the output of an asset or op and loading it as input to downstream assets or ops. For example, an I/O manager might store and load objects from files on a filesystem.Each software-defined asset can have its own I/O manager. In the multi-asset case where multiple assets are outputted, each outputted asset can be handled with a different I/O manager:
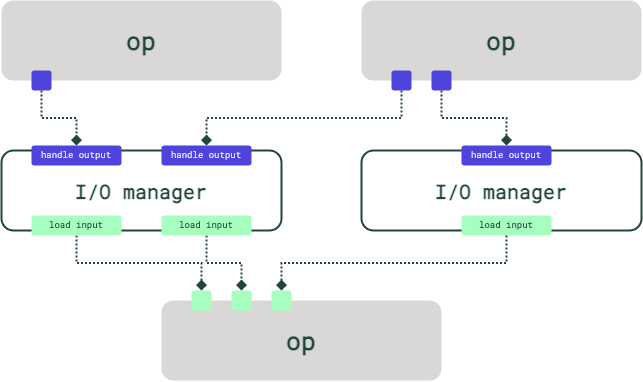
For ops, each op output can have its own I/O manager, or multiple op outputs can share an I/O manager. The I/O manager that's used for handling a particular op output is automatically used for loading it in downstream ops.
Consider the following diagram. In this example, a job has two I/O managers, each of which is shared across a few inputs and outputs:
Built-in I/O managers#
The default I/O manager, FilesystemIOManager, stores and retrieves values from pickle files in the local filesystem. If a job is invoked via JobDefinition.execute_in_process, the default I/O manager is switched to mem_io_manager, which stores outputs in memory.
Dagster provides out-of-the-box I/O managers for popular storage systems, such as Amazon S3 and Snowflake, or you can write your own:
- From scratch, or
- By extending the
UPathIOManagerif you want to store data in anfsspec-supported filesystem
For a full list of Dagster-provided I/O managers, refer to the built-in I/O managers list.
I/O managers are resources#
I/O managers are provided through the resources system, which means you can supply different I/O managers for the same assets or ops in different situations. For example, you might use an in-memory I/O manager for unit-testing and an Amazon S3 I/O manager in production.
Using I/O managers with Software-defined Assets#
Applying I/O managers to assets#
By default, materializing an asset named my_asset will pickle it to a local file named my_asset. The directory that file lives underneath is determined by the rules in FilesytemIOManager.
I/O managers enable fully overriding this behavior and storing asset contents in any way you wish - e.g. writing them as tables in a database or as objects in a cloud object store such as s3. You can use one of Dagster's built-in I/O managers, or you can write your own.
To apply an I/O manager to a set of assets, you can use Definitions:
from dagster_aws.s3 import S3PickleIOManager, S3Resource from dagster import Definitions, asset @asset def upstream_asset(): return [1, 2, 3] @asset def downstream_asset(upstream_asset): return upstream_asset + [4] defs = Definitions( assets=[upstream_asset, downstream_asset], resources={ "io_manager": S3PickleIOManager( s3_resource=S3Resource(), s3_bucket="my-bucket" ), }, )
This example also constructs an S3Resource because the S3PickleIOManager depends on the S3 resource. For more information on how these resource-resource dependencies are modeled, refer to the resources documentation.
When upstream_asset is materialized, the value [1, 2, 3] will be pickled and stored in an object on S3. When downstream_asset is materialized, the value of upstream_asset will be read from S3 and depickled, and [1, 2, 3, 4] will be pickled and stored in a different object on S3.
Per-asset I/O manager#
Different assets can have different I/O managers:
from dagster_aws.s3 import S3PickleIOManager, S3Resource from dagster import Definitions, FilesystemIOManager, asset @asset(io_manager_key="s3_io_manager") def upstream_asset(): return [1, 2, 3] @asset(io_manager_key="fs_io_manager") def downstream_asset(upstream_asset): return upstream_asset + [4] defs = Definitions( assets=[upstream_asset, downstream_asset], resources={ "s3_io_manager": S3PickleIOManager( s3_resource=S3Resource(), s3_bucket="my-bucket" ), "fs_io_manager": FilesystemIOManager(), }, )
When upstream_asset is materialized, the value [1, 2, 3] will be pickled and stored in an object on S3. When downstream_asset is materialized, the value of upstream_asset will be read from S3 and depickled, and [1, 2, 3, 4] will be pickled and stored in a file on the local filesystem.
In the multi-asset case, you can customize how each asset is materialized by specifying an io_manager_key on each output of the multi-asset.
from dagster import AssetOut, multi_asset @multi_asset( outs={ "s3_asset": AssetOut(io_manager_key="s3_io_manager"), "adls_asset": AssetOut(io_manager_key="adls2_io_manager"), }, ) def my_assets(): return "store_me_on_s3", "store_me_on_adls2"
The same assets can be bound to different resources and I/O managers in different environments. For example, for local development, you might want to store assets on your local filesystem while in production, you might want to store the assets in S3.
import os from dagster_aws.s3 import S3PickleIOManager, S3Resource from dagster import Definitions, FilesystemIOManager, asset @asset def upstream_asset(): return [1, 2, 3] @asset def downstream_asset(upstream_asset): return upstream_asset + [4] resources_by_env = { "prod": { "io_manager": S3PickleIOManager(s3_resource=S3Resource(), s3_bucket="my-bucket") }, "local": {"io_manager": FilesystemIOManager()}, } defs = Definitions( assets=[upstream_asset, downstream_asset], resources=resources_by_env[os.getenv("ENV", "local")], )
Asset input I/O managers#
In some cases you may need to load the input to an asset with different logic than that specified by the upstream asset's I/O manager.
To set an I/O manager for a particular input, use the input_manager_key argument on AssetIn.
In this example,first_asset and second_asset will be stored using the default I/O manager, but will be loaded as inputs to third_asset using the logic defined in the PandasSeriesIOManager (in this case loading as Pandas Series rather than Python lists).
@asset def first_asset() -> List[int]: return [1, 2, 3] @asset def second_asset() -> List[int]: return [4, 5, 6] @asset( ins={ "first_asset": AssetIn(input_manager_key="pandas_series"), "second_asset": AssetIn(input_manager_key="pandas_series"), } ) def third_asset(first_asset: pd.Series, second_asset: pd.Series) -> pd.Series: return pd.concat([first_asset, second_asset, pd.Series([7, 8])]) defs = Definitions( assets=[first_asset, second_asset, third_asset], resources={ "pandas_series": PandasSeriesIOManager(), }, )
Using I/O managers with non-asset jobs#
Job-wide I/O manager#
By default, all the inputs and outputs in a job use the same I/O manager. This I/O manager is determined by the ResourceDefinition provided for the "io_manager" resource key. "io_manager" is a resource key that Dagster reserves specifically for this purpose.
Here’s how to specify that all op outputs are stored using the FilesystemIOManager, which pickles outputs and stores them on the local filesystem. It stores files in a directory with the run ID in the path, so that outputs from prior runs will never be overwritten.
from dagster import FilesystemIOManager, job, op @op def op_1(): return 1 @op def op_2(a): return a + 1 @job(resource_defs={"io_manager": FilesystemIOManager()}) def my_job(): op_2(op_1())
Per-output I/O manager#
Not all the outputs in a job should necessarily be stored the same way. Maybe some of the outputs should live on the filesystem so they can be inspected, and others can be transiently stored in memory.
To select the I/O manager for a particular output, you can set an io_manager_key on Out, and then refer to that io_manager_key when setting I/O managers in your job. In this example, the output of op_1 will go to FilesystemIOManager and the output of op_2 will go to S3PickleIOManager.
from dagster_aws.s3 import S3PickleIOManager, S3Resource from dagster import FilesystemIOManager, Out, job, op @op(out=Out(io_manager_key="fs")) def op_1(): return 1 @op(out=Out(io_manager_key="s3_io")) def op_2(a): return a + 1 @job( resource_defs={ "fs": FilesystemIOManager(), "s3_io": S3PickleIOManager(s3_resource=S3Resource(), s3_bucket="test-bucket"), } ) def my_job(): op_2(op_1())
Per-input I/O manager#
Just as with the inputs to assets, the inputs to ops can be loaded using custom logic if you want to override the I/O manager of the upstream output. To set an I/O manager for a particular input, use the input_manager_key argument on In.
In this example, the output of op_1 will be stored using the default I/O manager, but will be loaded in op_2 using the logic defined in the PandasSeriesIOManager (in this case loading as Pandas Series rather than python lists).
@op def op_1(): return [1, 2, 3] @op(ins={"a": In(input_manager_key="pandas_series")}) def op_2(a): return pd.concat([a, pd.Series([4, 5, 6])]) @job(resource_defs={"pandas_series": pd_series_io_manager}) def a_job(): op_2(op_1())
Defining an I/O manager#
If you have specific requirements for where and how your outputs should be stored and retrieved, you can define your own I/O manager. This boils down to implementing two functions: one that stores outputs and one that loads inputs.
To define an I/O manager, extend the IOManager class. Oftentimes, you will want to extend the ConfigurableIOManager class (which subclasses IOManager) to attach a config schema to your I/O manager.
Here, we define a simple I/O manager that reads and writes CSV values to the filesystem. It takes an optional prefix path through config.
from dagster import ConfigurableIOManager, InputContext, OutputContext class MyIOManager(ConfigurableIOManager): # specifies an optional string list input, via config system path_prefix: List[str] = [] def _get_path(self, context) -> str: return "/".join(self.path_prefix + context.asset_key.path) def handle_output(self, context: OutputContext, obj): write_csv(self._get_path(context), obj) def load_input(self, context: InputContext): return read_csv(self._get_path(context))
The provided context argument for handle_output is an OutputContext. The provided context argument for load_input is an InputContext. The linked API documentation lists all the fields that are available on these objects.
Using an I/O manager factory#
If your I/O manager is more complex, or needs to manage internal state, it may make sense to split out the I/O manager definition from its configuration. In this case, you can use ConfigurableIOManagerFactory, which specifies config schema and implements a factory function that takes the config and returns an I/O manager.
In this case, we implement a stateful I/O manager which maintains a cache.
from dagster import IOManager, ConfigurableIOManagerFactory, OutputContext, InputContext import requests class ExternalIOManager(IOManager): def __init__(self, api_token): self._api_token = api_token # setup stateful cache self._cache = {} def handle_output(self, context: OutputContext, obj): ... def load_input(self, context: InputContext): if context.asset_key in self._cache: return self._cache[context.asset_key] ... class ConfigurableExternalIOManager(ConfigurableIOManagerFactory): api_token: str def create_io_manager(self, context) -> ExternalIOManager: return ExternalIOManager(self.api_token)
Defining Pythonic I/O managers#
Pythonic I/O managers are defined as subclasses of ConfigurableIOManager, and similarly to Pythonic resources specify any configuration fields as attributes. Each subclass must implement a handle_output and load_input method, which are called by Dagster at runtime to handle the storing and loading of data.
from dagster import ( Definitions, AssetKey, OutputContext, InputContext, ConfigurableIOManager, ) class MyIOManager(ConfigurableIOManager): root_path: str def _get_path(self, asset_key: AssetKey) -> str: return self.root_path + "/".join(asset_key.path) def handle_output(self, context: OutputContext, obj): write_csv(self._get_path(context.asset_key), obj) def load_input(self, context: InputContext): return read_csv(self._get_path(context.asset_key)) defs = Definitions( assets=..., resources={"io_manager": MyIOManager(root_path="/tmp/")}, )
Handling partitioned assets#
I/O managers can be written to handle partitioned assets. For a partitioned asset, each invocation of handle_output will (over)write a single partition, and each invocation of load_input will load one or more partitions. When the I/O manager is backed by a filesystem or object store, then each partition will typically correspond to a file or object. When it's backed by a database, then each partition will typically correspond to a range of rows in a table that fall within a particular window.
The default I/O manager has support for loading a partitioned upstream asset for a downstream asset with matching partitions out of the box (see the section below for loading multiple partitions). The UPathIOManager can be used to handle partitions in custom filesystem-based I/O managers.
To handle partitions in an custom I/O manager, you'll need to determine which partition you're dealing with when you're storing an output or loading an input. For this, OutputContext and InputContext have a asset_partition_key property:
class MyPartitionedIOManager(IOManager): def _get_path(self, context) -> str: if context.has_partition_key: return "/".join(context.asset_key.path + [context.asset_partition_key]) else: return "/".join(context.asset_key.path) def handle_output(self, context: OutputContext, obj): write_csv(self._get_path(context), obj) def load_input(self, context: InputContext): return read_csv(self._get_path(context))
If you're working with time window partitions, you can also use the asset_partitions_time_window property, which will return a TimeWindow object.
Handling partition mappings#
A single partition of one asset might depend on a range of partitions of an upstream asset.
The default I/O manager has support for loading multiple upstream partitions. In this case, the downstream asset should use Dict[str, ...] (or leave it blank) type for the upstream DagsterType. Here is an example of loading multiple upstream partitions using the default partition mapping:
from datetime import datetime from typing import Dict import pandas as pd from dagster import ( AssetExecutionContext, DailyPartitionsDefinition, HourlyPartitionsDefinition, asset, materialize, ) start = datetime(2022, 1, 1) hourly_partitions = HourlyPartitionsDefinition(start_date=f"{start:%Y-%m-%d-%H:%M}") daily_partitions = DailyPartitionsDefinition(start_date=f"{start:%Y-%m-%d}") @asset(partitions_def=hourly_partitions) def upstream_asset(context: AssetExecutionContext) -> pd.DataFrame: return pd.DataFrame({"date": [context.partition_key]}) @asset( partitions_def=daily_partitions, ) def downstream_asset(upstream_asset: Dict[str, pd.DataFrame]) -> pd.DataFrame: return pd.concat(list(upstream_asset.values())) result = materialize( [*upstream_asset.to_source_assets(), downstream_asset], partition_key=start.strftime(daily_partitions.fmt), ) downstream_asset_data = result.output_for_node("downstream_asset", "result") assert ( len(downstream_asset_data) == 24 ), "downstream day should map to upstream 24 hours"
The upstream_asset becomes a mapping from partition keys to partition values. This is a property of the default I/O manager or any I/O manager inheriting from the UPathIOManager.
A PartitionMapping can be provided to AssetIn to configure the mapped upstream partitions.
When writing a custom I/O manager for loading multiple upstream partitions, the mapped keys can be accessed using InputContext.asset_partition_keys, InputContext.asset_partition_key_range, or InputContext.asset_partitions_time_window.
Writing a per-input I/O manager#
In some cases you may find that you need to load an input in a way other than the load_input function of the corresponding output's I/O manager. For example, let's say Team A has an op that returns an output as a Pandas DataFrame and specifies an I/O manager that knows how to store and load Pandas DataFrames. Your team is interested in using this output for a new op, but you are required to use PySpark to analyze the data. Unfortunately, you don't have permission to modify Team A's I/O manager to support this case. Instead, you can specify an input manager on your op that will override some of the behavior of Team A's I/O manager.
Since the method for loading an input is directly affected by the way the corresponding output was stored, we recommend defining your input managers as subclasses of existing I/O managers and just updating the load_input method. In this example, we load an input as a NumPy array rather than a Pandas DataFrame by writing the following:
# in this case PandasIOManager is an existing IO Manager class MyNumpyLoader(PandasIOManager): def load_input(self, context: InputContext) -> np.ndarray: file_path = "path/to/dataframe" array = np.genfromtxt(file_path, delimiter=",", dtype=None) return array @op(ins={"np_array_input": In(input_manager_key="numpy_manager")}) def analyze_as_numpy(np_array_input: np.ndarray): assert isinstance(np_array_input, np.ndarray) @job(resource_defs={"numpy_manager": MyNumpyLoader(), "io_manager": PandasIOManager()}) def my_job(): df = produce_pandas_output() analyze_as_numpy(df)
This may quickly run into issues if the owner of PandasIOManager changes the path at which they store outputs. We recommend splitting out path defining logic (or other computations shared by handle_output and load_input) into new methods that are called when needed.
# this IO Manager is owned by a different team class BetterPandasIOManager(ConfigurableIOManager): def _get_path(self, output_context): return os.path.join( self.base_dir, "storage", f"{output_context.step_key}_{output_context.name}.csv", ) def handle_output(self, context: OutputContext, obj: pd.DataFrame): file_path = self._get_path(context) os.makedirs(os.path.dirname(file_path), exist_ok=True) if obj is not None: obj.to_csv(file_path, index=False) def load_input(self, context: InputContext) -> pd.DataFrame: return pd.read_csv(self._get_path(context.upstream_output)) # write a subclass that uses _get_path for your custom loading logic class MyBetterNumpyLoader(BetterPandasIOManager): def load_input(self, context: InputContext) -> np.ndarray: file_path = self._get_path(context.upstream_output) array = np.genfromtxt(file_path, delimiter=",", dtype=None) return array @op(ins={"np_array_input": In(input_manager_key="better_numpy_manager")}) def better_analyze_as_numpy(np_array_input: np.ndarray): assert isinstance(np_array_input, np.ndarray) @job( resource_defs={ "numpy_manager": MyBetterNumpyLoader(), "io_manager": BetterPandasIOManager(), } ) def my_better_job(): df = produce_pandas_output() better_analyze_as_numpy(df)
Examples#
A custom I/O manager that stores Pandas DataFrames in tables#
If your ops produce Pandas DataFrames that populate tables in a data warehouse, you might write something like the following. This I/O manager uses the name assigned to the output as the name of the table to write the output to.
from dagster import ConfigurableIOManager, io_manager class DataframeTableIOManager(ConfigurableIOManager): def handle_output(self, context: OutputContext, obj): # name is the name given to the Out that we're storing for table_name = context.name write_dataframe_to_table(name=table_name, dataframe=obj) def load_input(self, context: InputContext): # upstream_output.name is the name given to the Out that we're loading for if context.upstream_output: table_name = context.upstream_output.name return read_dataframe_from_table(name=table_name) @job(resource_defs={"io_manager": DataframeTableIOManager()}) def my_job(): op_2(op_1())
Custom filesystem-based I/O manager#
Dagster provides a feature-rich base class for filesystem-based I/O managers: UPathIOManager. It's compatible with both local and remote filesystems (like S3 or GCS) by using universal-pathlib and fsspec. The full list of supported filesystems can be found here. The UPathIOManager also has other important features:
- handles partitioned assets
- handles loading a single upstream partition
- handles loading multiple upstream partitions (with respect to
PartitionMapping) - the
get_metadatamethod can be customized to add additional metadata to the output - the
allow_missing_partitionsmetadata value can be set toTrueto skip missing partitions (the default behavior is to raise an error)
The default I/O manager inherits from the UPathIOManager and therefore has these features too.
The UPathIOManager already implements the load_input and handle_output methods. Instead, if you want to write a custom UPathIOManager the UPathIOManager.dump_to_path and UPathIOManager.load_from_path for a given universal_pathlib.UPath should to be implemented. Here are some examples:
import pandas as pd from upath import UPath from dagster import ( InputContext, OutputContext, UPathIOManager, ) class PandasParquetIOManager(UPathIOManager): extension: str = ".parquet" def dump_to_path(self, context: OutputContext, obj: pd.DataFrame, path: UPath): with path.open("wb") as file: obj.to_parquet(file) def load_from_path(self, context: InputContext, path: UPath) -> pd.DataFrame: with path.open("rb") as file: return pd.read_parquet(file)
The extension attribute defines the suffix all the file paths generated by the IOManager will end with.
The I/O managers defined above will work with partitioned assets on any filesystem:
from typing import Optional from dagster import ConfigurableIOManagerFactory, EnvVar class LocalPandasParquetIOManager(ConfigurableIOManagerFactory): base_path: Optional[str] = None def create_io_manager(self, context) -> PandasParquetIOManager: base_path = UPath(self.base_path or context.instance.storage_directory()) return PandasParquetIOManager(base_path=base_path) class S3ParquetIOManager(ConfigurableIOManagerFactory): base_path: str aws_access_key: str = EnvVar("AWS_ACCESS_KEY_ID") aws_secret_key: str = EnvVar("AWS_SECRET_ACCESS_KEY") def create_io_manager(self, context) -> PandasParquetIOManager: base_path = UPath(self.base_path) assert str(base_path).startswith("s3://"), base_path return PandasParquetIOManager(base_path=base_path)
Notice how the local and S3 I/O managers are practically the same - the only difference is in the required resources.
Providing per-output metadata to an I/O manager#
You might want to provide static metadata that controls how particular outputs are stored. You don't plan to change the metadata at runtime, so it makes more sense to attach it to a definition rather than expose it as a configuration option.
For example, if your job produces DataFrames to populate tables in a data warehouse, you might want to specify that each output always goes to a particular table. To accomplish this, you can define metadata on each Out:
@op(out=Out(metadata={"schema": "some_schema", "table": "some_table"})) def op_1(): """Return a Pandas DataFrame.""" @op(out=Out(metadata={"schema": "other_schema", "table": "other_table"})) def op_2(_input_dataframe): """Return a Pandas DataFrame."""
The I/O manager can then access this metadata when storing or retrieving data, via the OutputContext.
In this case, the table names are encoded in the job definition. If, instead, you want to be able to set them at run time, the next section describes how.
class MyIOManager(ConfigurableIOManager): def handle_output(self, context: OutputContext, obj): if context.definition_metadata: table_name = context.definition_metadata["table"] schema = context.definition_metadata["schema"] write_dataframe_to_table(name=table_name, schema=schema, dataframe=obj) else: raise Exception( f"op {context.op_def.name} doesn't have schema and metadata set" ) def load_input(self, context: InputContext): if context.upstream_output and context.upstream_output.definition_metadata: table_name = context.upstream_output.definition_metadata["table"] schema = context.upstream_output.definition_metadata["schema"] return read_dataframe_from_table(name=table_name, schema=schema) else: raise Exception("Upstream output doesn't have schema and metadata set")
Per-input loading in assets#
Let's say you have an asset that is set to store and load as a Pandas DataFrame, but you want to write a new asset that processes the first asset as a NumPy array. Rather than update the I/O manager of the first asset to be able to load as a Pandas DataFrame and a NumPy array, you can write a new loader for the new asset.
In this example, we store upstream_asset as a Pandas DataFrame, and we write a new I/O manager to load is as a NumPy array in downstream_asset
class PandasAssetIOManager(ConfigurableIOManager): def handle_output(self, context: OutputContext, obj): file_path = self._get_path(context) store_pandas_dataframe(name=file_path, table=obj) def _get_path(self, context): return os.path.join( "storage", f"{context.asset_key.path[-1]}.csv", ) def load_input(self, context: InputContext) -> pd.DataFrame: file_path = self._get_path(context) return load_pandas_dataframe(name=file_path) class NumpyAssetIOManager(PandasAssetIOManager): def load_input(self, context: InputContext) -> np.ndarray: file_path = self._get_path(context) return load_numpy_array(name=file_path) @asset(io_manager_key="pandas_manager") def upstream_asset() -> pd.DataFrame: return pd.DataFrame([1, 2, 3]) @asset( ins={"upstream": AssetIn(key_prefix="public", input_manager_key="numpy_manager")} ) def downstream_asset(upstream: np.ndarray) -> tuple: return upstream.shape defs = Definitions( assets=[upstream_asset, downstream_asset], resources={ "pandas_manager": PandasAssetIOManager(), "numpy_manager": NumpyAssetIOManager(), }, )
Testing an I/O manager#
The easiest way to test an I/O manager is to construct an OutputContext or InputContext and pass it to the handle_output or load_input method of the I/O manager. The build_output_context and build_input_context functions allow for easy construction of these contexts.
Here's an example for a simple I/O manager that stores outputs in an in-memory dictionary that's keyed on the step and name of the output.
from dagster import ( InputContext, IOManager, OutputContext, build_input_context, build_output_context, ) class MyIOManager(IOManager): def __init__(self): self.storage_dict = {} def handle_output(self, context: OutputContext, obj): self.storage_dict[(context.step_key, context.name)] = obj def load_input(self, context: InputContext): if context.upstream_output: return self.storage_dict[ (context.upstream_output.step_key, context.upstream_output.name) ] def test_my_io_manager_handle_output(): manager = MyIOManager() context = build_output_context(name="abc", step_key="123") manager.handle_output(context, 5) assert manager.storage_dict[("123", "abc")] == 5 def test_my_io_manager_load_input(): manager = MyIOManager() manager.storage_dict[("123", "abc")] = 5 context = build_input_context( upstream_output=build_output_context(name="abc", step_key="123") ) assert manager.load_input(context) == 5
Recording metadata from an I/O manager#
Sometimes, you may want to record some metadata while handling an output in an I/O manager. To do this, you can invoke OutputContext.add_output_metadata from within the body of the handle_output function. Using this, we can modify one of the above examples to now include some helpful metadata in the log:
class DataframeTableIOManagerWithMetadata(ConfigurableIOManager): def handle_output(self, context: OutputContext, obj): table_name = context.name write_dataframe_to_table(name=table_name, dataframe=obj) context.add_output_metadata({"num_rows": len(obj), "table_name": table_name}) def load_input(self, context: InputContext): if context.upstream_output: table_name = context.upstream_output.name return read_dataframe_from_table(name=table_name)
Any entries yielded this way will be attached to the Handled Output event for this output.
Additionally, if the handled output is part of a software-defined asset, these metadata entries will also be attached to the materialization event created for that asset and show up on the Asset Details page for the asset.
See it in action#
For more examples of I/O managers, check out the following in our Hacker News example:
Our Type and Metadata example also covers writing custom I/O managers.
References#
Built-in I/O managers#
| Name | Description | Additional Documentation |
|---|---|---|
FilesystemIOManager | Default I/O manager. Stores outputs as pickle files on the local file system. | |
InMemoryIOManager | Stores outputs in memory. Primarily useful for unit testing. | |
S3PickleIOManager | Stores outputs as pickle files in Amazon Web Services S3. | |
ConfigurablePickledObjectADLS2IOManager | Stores outputs as pickle files in Azure ADLS2. | |
GCSPickleIOManager | Stores outputs as pickle files in Google Cloud Platform GCS. | |
BigQueryPandasIOManager | Stores Pandas DataFrame outputs in Google Cloud Platform BigQuery. | Tutorial, Reference Guide |
BigQueryPySparkIOManager | Stores PySpark DataFrame outputs in Google Cloud Platform BigQuery. | Tutorial, Reference Guide |
SnowflakePandasIOManager | Stores Pandas DataFrame outputs in Snowflake. | Tutorial, Reference Guide |
SnowflakePySparkIOManager | Stores PySpark DataFrame outputs in Snowflake. | Tutorial, Reference Guide |
DuckDBPandasIOManager | Stores Pandas DataFrame outputs in DuckDB. | |
DuckDBPySparkIOManager | Stores PySpark DataFrame outputs in DuckDB. | |
DuckDBPolarsIOManager | Stores Polars DataFrame outputs in DuckDB. |
Relevant APIs#
| Name | Description | |
|---|---|---|
ConfigurableIOManager | A base class used to define configurable I/O managers, which are also configurable resources. | |
ConfigurableIOManagerFactory | A base class used to specify configuration for more advanced I/O managers, where configuration is separate from the IOManager implementation class. | |
IOManager | Base class for standalone I/O managers which are constructed by ConfigurableIOManagerFactories. | |
build_input_context | Function for directly constructing an InputContext, to be passed to the IOManager.load_input method. This is designed primarily for testing purposes. | |
build_output_context | Function for directly constructing an OutputContext, to be passed to the IOManager.handle_output method. This is designed primarily for testing purposes. |