Fivetran & Dagster#
Dagster can orchestrate your Fivetran connectors, making it easy to chain a Fivetran sync with upstream or downstream steps in your workflow.
This guide focuses on how to work with Fivetran connectors using Dagster's software-defined asset (SDA) framework.
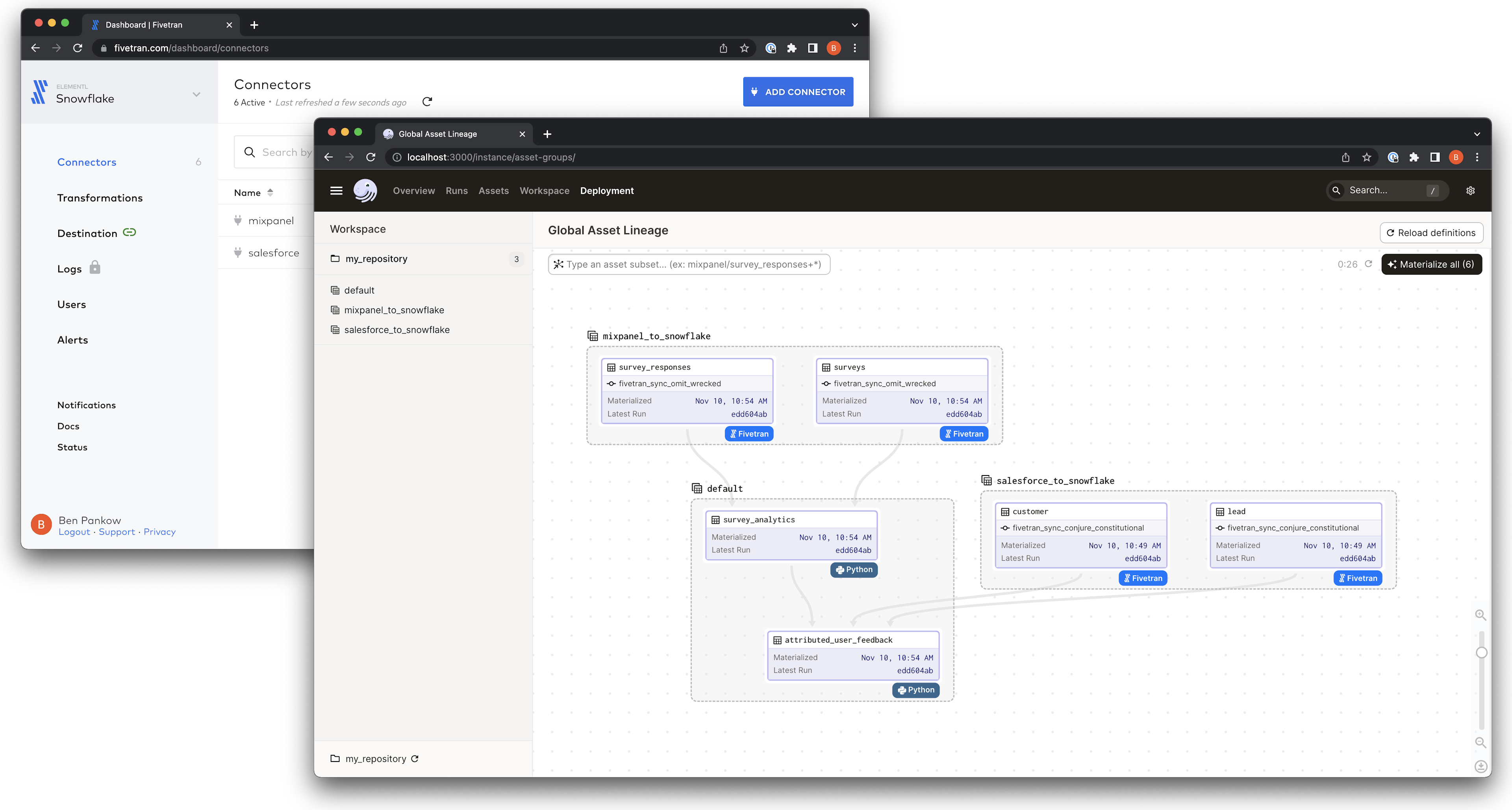
Fivetran connectors and Dagster assets#
A Fivetran connector defines a series of schemas and tables which are synced between a source and a destination. During a sync, data is retrieved from the source and written to the destination as one or more tables. Dagster represents each of the replicas generated in the destination as an asset. This enables you to easily:
- Visualize the schemas and tables involved in a Fivetran connector and execute a sync from Dagster
- Define downstream computations which depend on replicas produced by Fivetran
- Track historical metadata and logs for each table
- Track data lineage through Fivetran and other tools
Prerequisites#
To get started, you'll need to install the dagster and dagster-fivetran Python packages:
pip install dagster dagster-fivetran
You'll also want to set up a Fivetran instance and have a Fivetran API key and API secret, which can be generated by a Fivetran Account Administrator.
Step 1: Connecting to Fivetran#
The first step in using Fivetran with Dagster is to tell Dagster how to connect to your Fivetran instance using a Fivetran resource. This resource contains the credentials needed to access your Fivetran instance.
We will supply our credentials as environment variables. For more information on setting environment variables in a production setting, see Using environment variables and secrets.
export FIVETRAN_API_KEY=... export FIVETRAN_API_SECRET=...
Then, we can instruct Dagster to authorize the Fivetran resource using the environment variables:
from dagster_fivetran import FivetranResource from dagster import EnvVar # Pull API key and secret from environment variables fivetran_instance = FivetranResource( api_key=EnvVar("FIVETRAN_API_KEY"), api_secret=EnvVar("FIVETRAN_API_SECRET"), )
For more information on the additional configuration options available for the Fivetran resource, see the API reference.
Step 2: Loading Fivetran asset definitions into Dagster#
The easiest way to get started using Fivetran with Dagster is to have Dagster automatically generate asset defintions from your Fivetran project. You can load asset definitions from a Fivetran instance via API, at initialization time.
You can also manually-build asset definitions on a per-connector basis.
Loading Fivetran asset definitions from a Fivetran instance#
To load Fivetran assets into Dagster from your Fivetran instance, you'll need to supply the Fivetran resource that we defined above in Step 1. Here, the Fivetran instance is treated as the source of truth.
from dagster_fivetran import load_assets_from_fivetran_instance # Use the fivetran_instance resource we defined in Step 1 fivetran_assets = load_assets_from_fivetran_instance(fivetran_instance)
The load_assets_from_fivetran_instance function retrieves all of the connectors you have defined in the Fivetran interface, creating a Dagster asset for each generated table. Each connector has an associated op which triggers a sync of that connector.
Step 3: Adding downstream assets#
Once your Fivetran assets are loaded into Dagster, you can create assets which depend on them. These can be other assets pulled in from external sources such as dbt or assets defined in Python code.
In this case, we have a Fivetran connector that stores data in the public.survey_responses table in Snowflake. The corresponding asset key is public/survey_responses. We specify the output IO manager to tell downstream assets how to retreive the data.
import json from dagster_fivetran import ( FivetranResource, load_assets_from_fivetran_instance, ) from dagster import ( ScheduleDefinition, define_asset_job, asset, AssetIn, AssetKey, Definitions, AssetSelection, EnvVar, Definitions, ) from dagster_snowflake_pandas import SnowflakePandasIOManager fivetran_instance = FivetranResource( api_key=EnvVar("FIVETRAN_API_KEY"), api_secret=EnvVar("FIVETRAN_API_SECRET"), ) fivetran_assets = load_assets_from_fivetran_instance( fivetran_instance, io_manager_key="snowflake_io_manager", ) @asset( ins={ "survey_responses": AssetIn( key=AssetKey(["public", "survey_responses"]) ) } ) def survey_responses_file(survey_responses): with open("survey_responses.json", "w", encoding="utf8") as f: f.write(json.dumps(survey_responses, indent=2)) # only run the airbyte syncs necessary to materialize survey_responses_file my_upstream_job = define_asset_job( "my_upstream_job", AssetSelection.assets(survey_responses_file) .upstream() # all upstream assets (in this case, just the survey_responses Fivetran asset) .required_multi_asset_neighbors(), # all Fivetran assets linked to the same connection ) defs = Definitions( jobs=[my_upstream_job], assets=[fivetran_assets, survey_responses_file], resources={"snowflake_io_manager": SnowflakePandasIOManager(...)}, )
Step 4: Scheduling Fivetran syncs#
Once you have Fivetran assets, you can define a job that runs some or all of these assets on a schedule and triggers the underlying Fivetran sync:
from dagster_fivetran import FivetranResource, load_assets_from_fivetran_instance from dagster import ( ScheduleDefinition, define_asset_job, AssetSelection, EnvVar, Definitions, ) fivetran_instance = FivetranResource( api_key=EnvVar("FIVETRAN_API_KEY"), api_secret=EnvVar("FIVETRAN_API_SECRET"), ) fivetran_assets = load_assets_from_fivetran_instance(fivetran_instance) # materialize all assets run_everything_job = define_asset_job("run_everything", selection="*") # only run my_fivetran_connection and downstream assets my_etl_job = define_asset_job( "my_etl_job", AssetSelection.groups("my_fivetran_connection").downstream() ) defs = Definitions( assets=[fivetran_assets], schedules=[ ScheduleDefinition( job=my_etl_job, cron_schedule="@daily", ), ScheduleDefinition( job=run_everything_job, cron_schedule="@weekly", ), ], )
Refer to the Schedule documentation for more info on running jobs on a schedule.
What's next?#
If you find a bug or want to add a feature to the dagster-fivetran library, we invite you to contribute.