Asset versioning and caching#
This guide demonstrates how to build memoizable graphs of assets. Memoizable assets help avoid unnecessary recomputations, speed up the developer workflow, and save computational resources.
Context#
There's no reason to spend time materializing an asset if the result is going to be the same as the result of its last materialization.
Dagster's versioning system helps you determine ahead of time whether materializing an asset will produce a different result. It's based on the idea that the result of an asset materialization shouldn't change as long as:
- The code used is the same code as the last time the asset was materialized.
- The input data is the same input data as the last time the asset was materialized.
Dagster has two versioning concepts to represent the code and input data used for each materialization:
- Code version. A string that represents the version of the code that computes an asset. This is the
code_versionargument of@asset. - Data version. A string that represents the version of the data represented by the asset. This is represented as a
DataVersionobject.
By keeping track of code and data versions, Dagster can predict whether a materialization will change the underlying value. This allows Dagster to skip redundant materializations and instead return the previously computed value. In more technical terms, Dagster offers a limited form of memoization for assets: the last-computed asset value is always cached.
In computationally expensive data pipelining, this approach can yield tremendous benefits.
Step one: Understanding data versions#
By default, Dagster automatically computes a data version for each materialization of an asset. It does this by hashing a code version together with the data versions of any input assets.
Let's start with a trivial asset that returns a hardcoded number:
from dagster import asset @asset def a_number(): return 1
Next, start the Dagster UI:
dagster dev
Navigate to the Asset catalog and click Materialize to materialize the asset.
Next, look at the entry for the materialization. Take note of the two hashes in the System tags section of the materialization details - code_version and data_version:
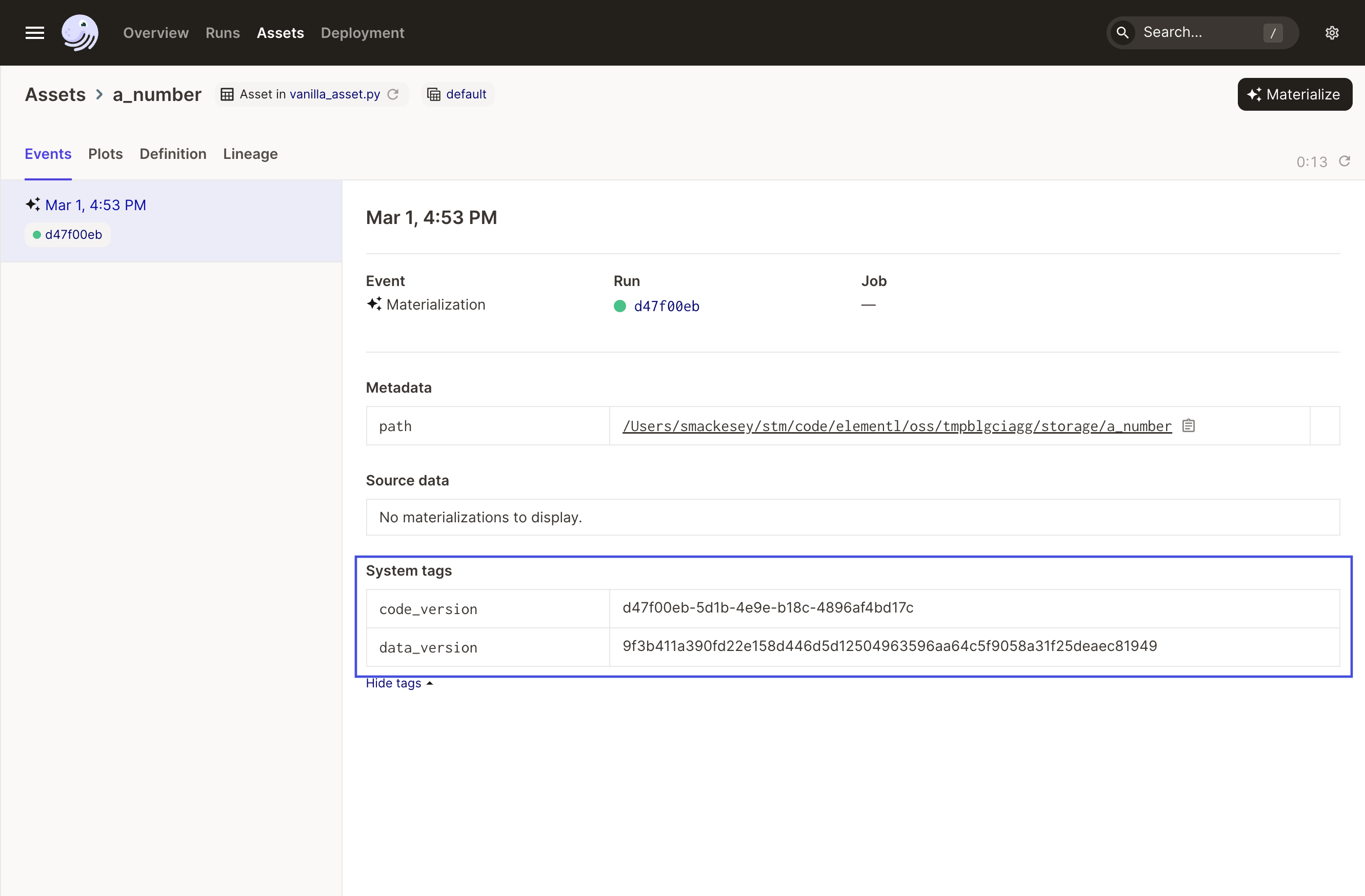
The code version shown is a copy of the run ID for the run that generated this materialization. Because a_number has no user-defined code_version, Dagster assumes a different code version on every run, which it represents with the run ID.
The data_version is also generated by Dagster. This is a hash of the code version together with the data versions of any inputs. Since a_number has no inputs, in this case, the data version is a hash of the code version only.
If you materialize the asset again, you'll notice that both the code version and data version change. The code version becomes the ID of the new run and the data version becomes a hash of the new code version.
Let's improve this situation by setting an explicit code version. Add a code_version on the asset:
from dagster import asset @asset(code_version="v1") def versioned_number(): return 1
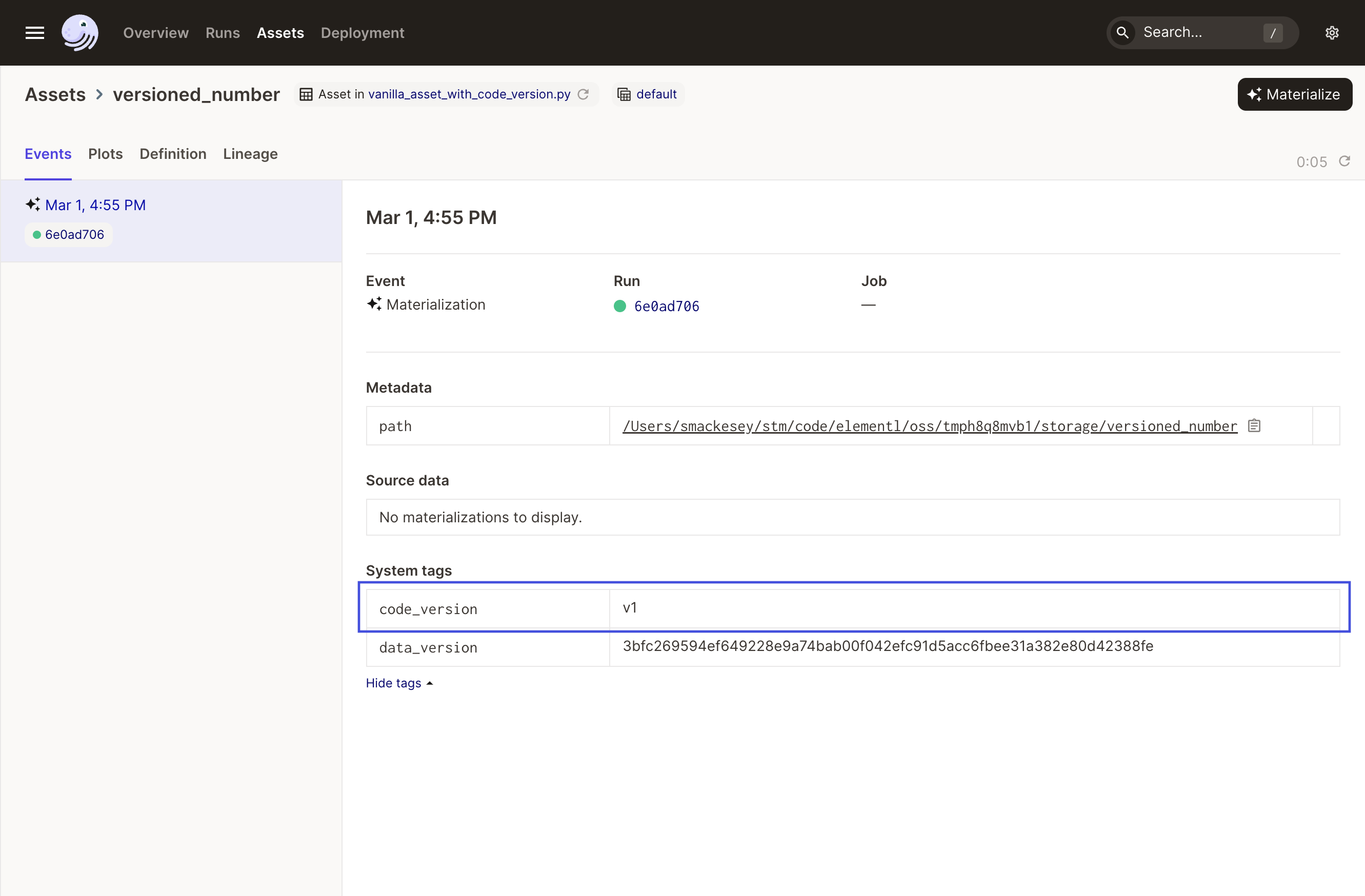
Now, materialize the asset. The user-defined code version v1 will be associated with the latest materialization:
Now, let's update the code and inform Dagster that the code has changed. Do this by changing the code_version argument:
from dagster import asset @asset(code_version="v2") def versioned_number(): return 11
Click Reload definitions to pick up the changes.
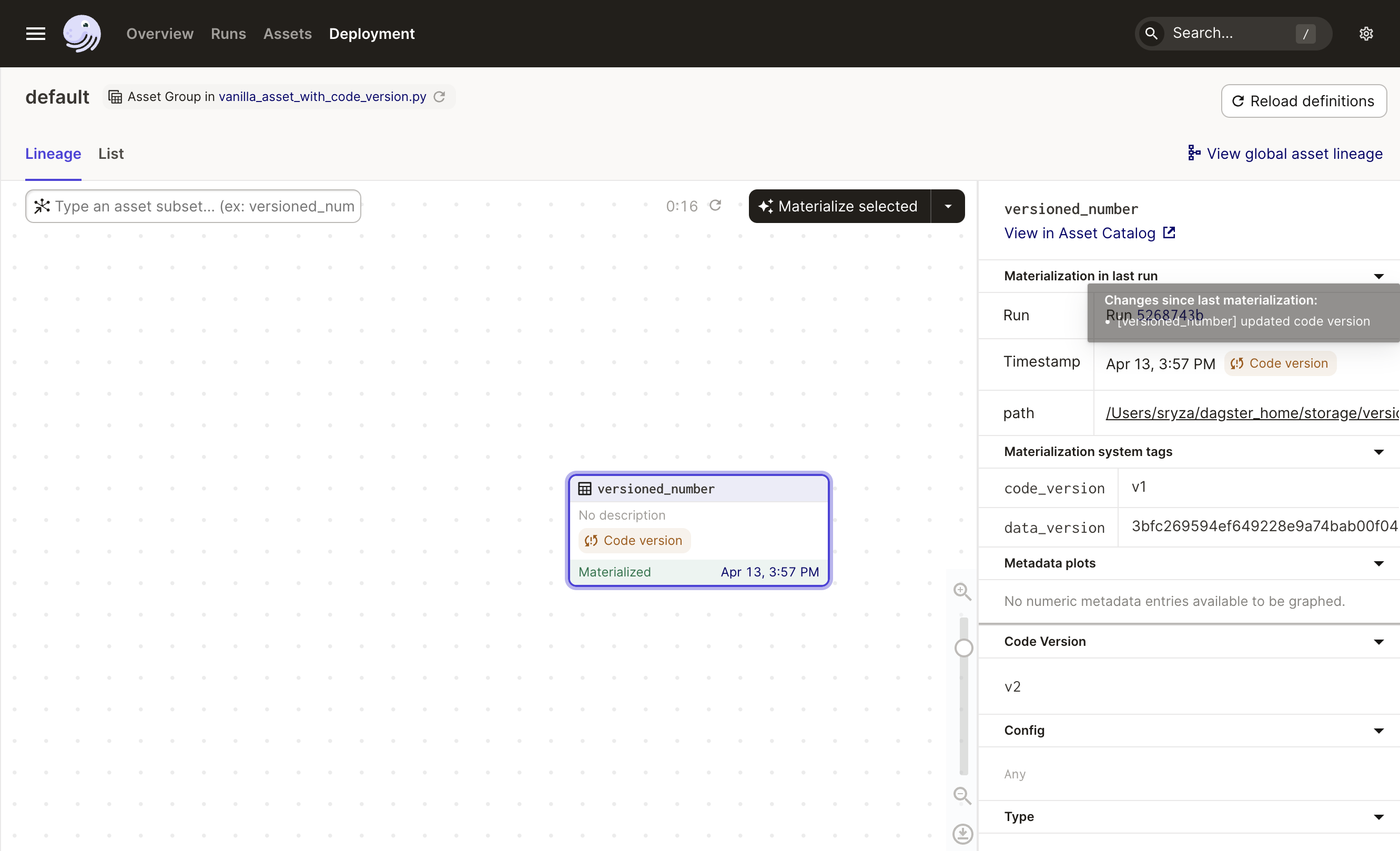
The asset now has a label to indicate that its code version has changed since it was last materialized. We can see this in both the asset graph and the sidebar, where details about the last materialization of a selected node are visible. You can see the code version associated with the last materialization of versioned_number is v1, but its current code version is v2. This is also explained in the tooltip that appears if you hover over the (i) icon on the indicator tag.
The versioned_number asset must be materialized again to become up-to-date. Click the toggle to the right side of the Materialize button to display the Propagate changes option. Clicking this will propagate the changed code version by materializing versioned_number. This will update the latest materialization code_version shown in the sidebar to v2 and bring the asset up-to-date.
Step two: data versions with dependencies#
Tracking changes becomes more powerful when there are dependencies in play. Let's add an asset downstream of our first asset:
from dagster import asset @asset(code_version="v2") def versioned_number(): return 11 @asset(code_version="v1") def multiplied_number(versioned_number): return versioned_number * 2
In the Dagster UI, click Reload definitions. The multipled_number asset will be marked as Never materialized.
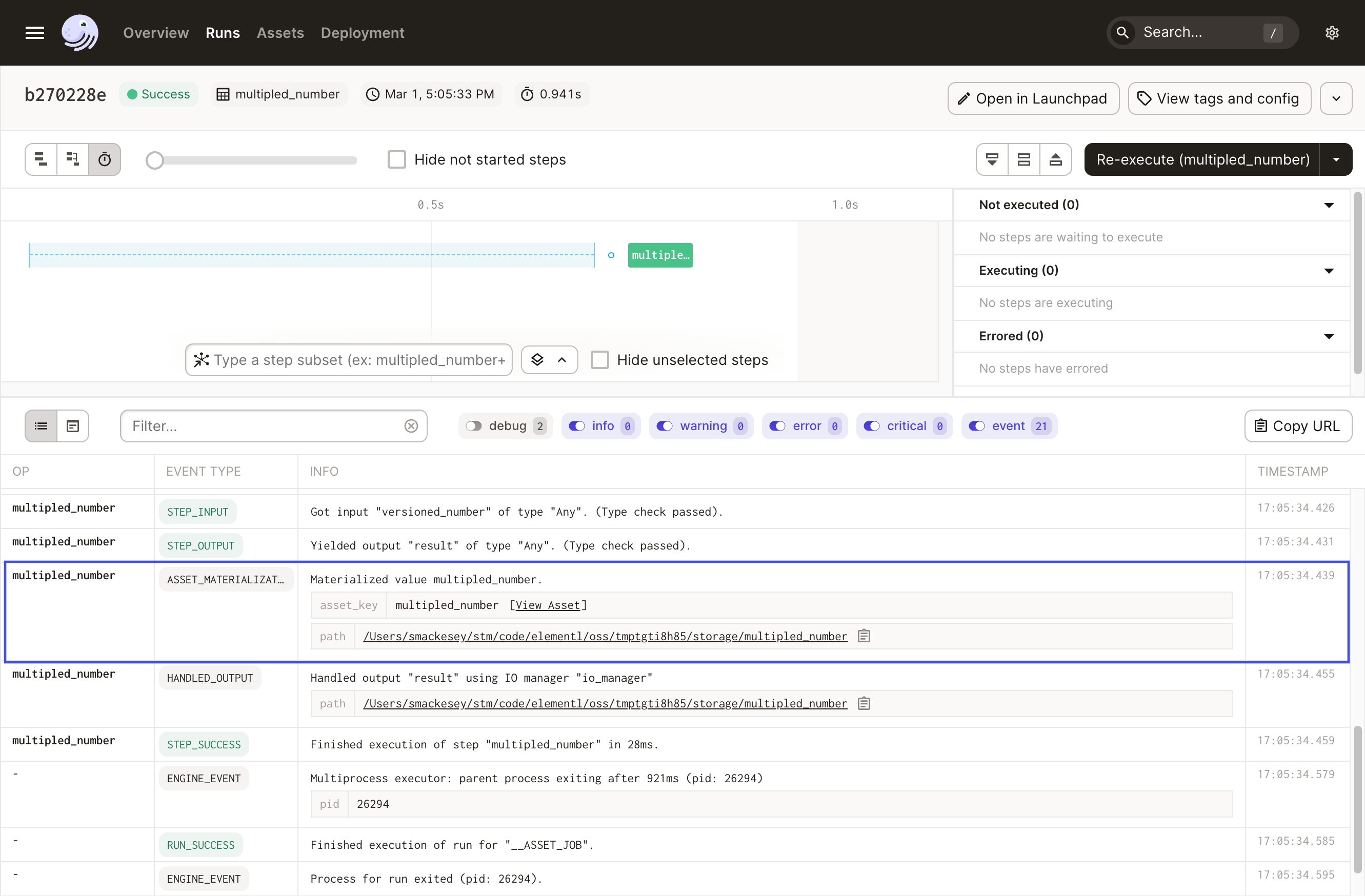
Next, click the toggle to the right side of the Materialize button to display the Propagate changes option. As the Materialize button ignores versioning, we need this option to ensure the multipled_number asset is properly materialized.
In the created run, only the step associated with multiplied_number is run. The system knows that versioned_number is up to date and therefore can safely skip that computation. You can see this on the details page for the run:
Now, let's update the versioned_number asset. Specifically, we'll change its return value and code version:
from dagster import asset @asset(code_version="v3") def versioned_number(): return 15 @asset(code_version="v1") def multiplied_number(versioned_number): return versioned_number * 2
As before, this will cause versioned_number to get a label indicating that its code version has changed since its latest materialization. But since multiplied_number depends on versioned_number, it must be recomputed as well and so gets a label indicating that the code version of an upstream asset has changed. If you hover over the Upstream code version tag on multiplied_number, you will see the upstream asset whose code version has changed:
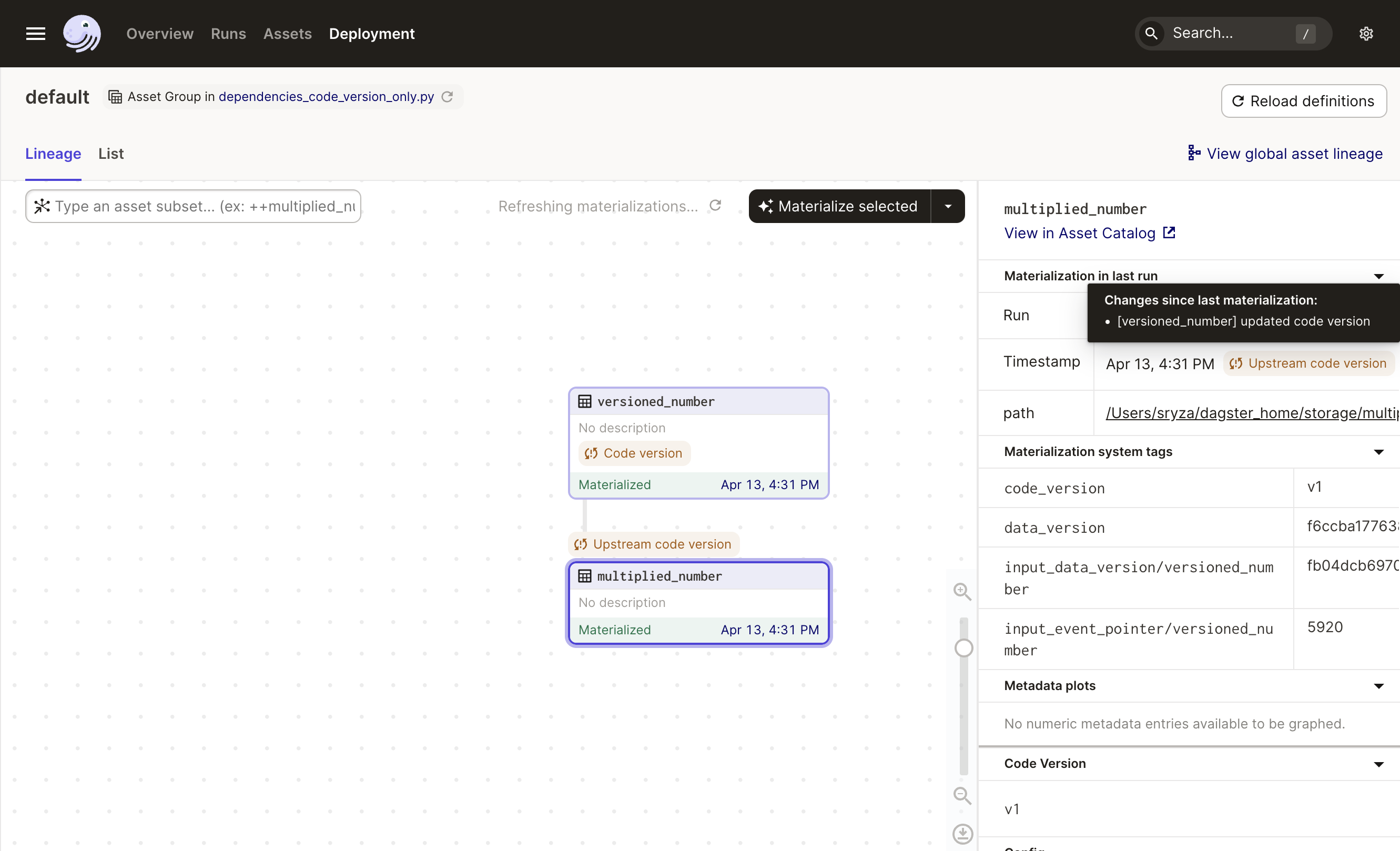
Click Propagate changes to get both assets up-to-date again.
Step three: Computing your own data versions#
A data version is like a fingerprint for the value that an asset represents, i.e. the output of its materialization function. Therefore, we want our data versions to correspond on a one-to-one basis to the possible return values of a materialization function. Dagster auto-generates data versions by hashing the code version together with input data versions. This satisfies the above criterion in many cases, but sometimes a different approach is necessary.
For example, when a materialization function contains an element of randomness, then multiple materializations of the asset with the same code over the same inputs will produce the same data version for different outputs. On the flip side, if we are generating code versions with an automated approach like source-hashing, then materializing an asset after a cosmetic refactor will produce a different data version (which is derived from the code version) but the same output.
Dagster accommodates these and similar scenarios by allowing user code to supply its own data versions. To do so, include the data version alongside the returned asset value in an Output object. Let's update versioned_number to do this. For simplicity, you'll use the stringified return value as the data version:
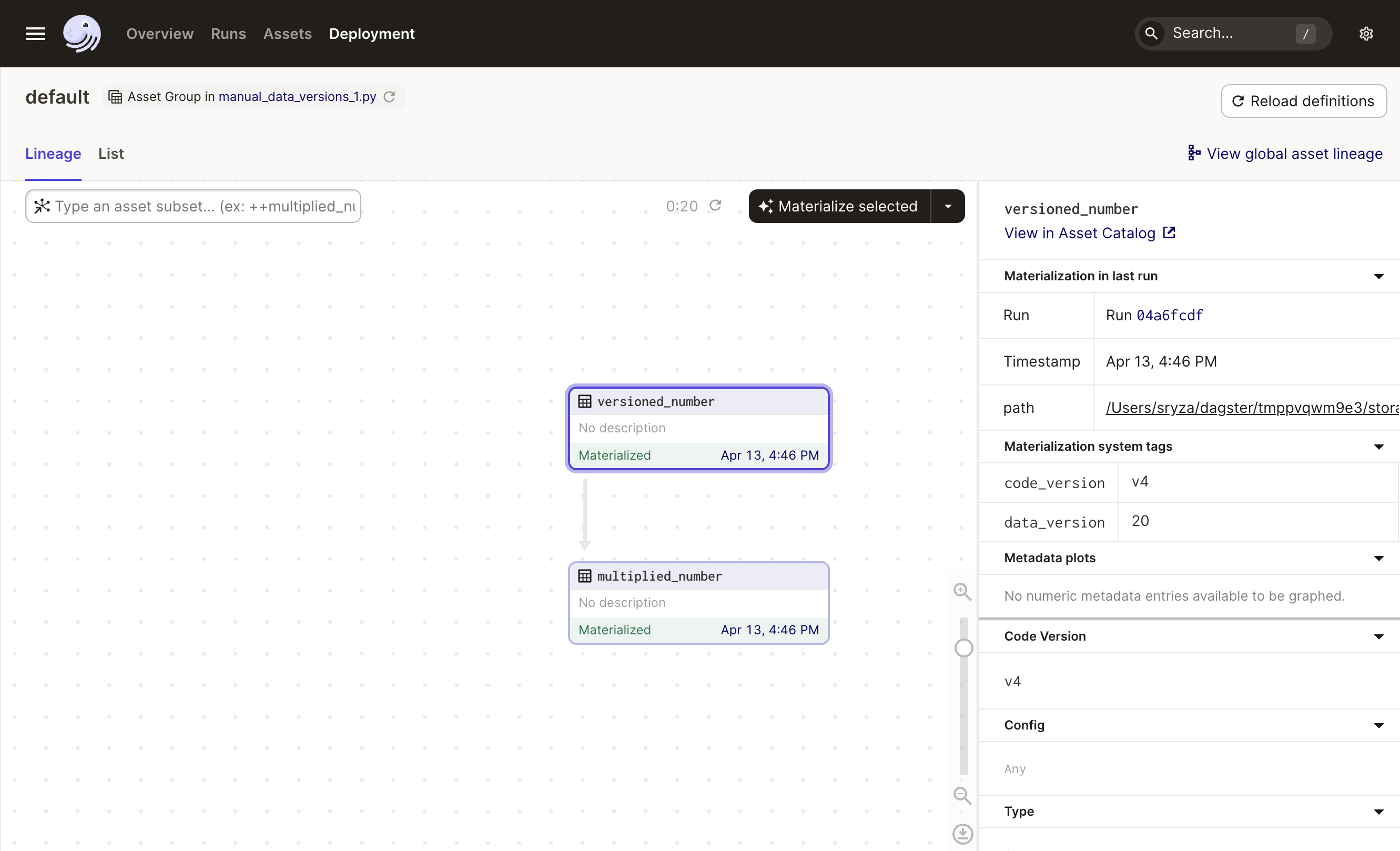
from dagster import DataVersion, Output, asset @asset(code_version="v4") def versioned_number(): value = 20 return Output(value, data_version=DataVersion(str(value))) @asset(code_version="v1") def multiplied_number(versioned_number): return versioned_number * 2
Both assets get labels to indicate that they're impacted by the new code version of versioned_number. Let's re-materialize them both to make them fresh. Notice the DataVersion of versioned_number is now 20:
Let's simulate a cosmetic refactor by updating versioned_number again, but without changing the returned value. Bump the code version to v5 and change 20 to 10 + 10:
from dagster import DataVersion, Output, asset @asset(code_version="v5") def versioned_number(): value = 10 + 10 return Output(value, data_version=DataVersion(str(value))) @asset(code_version="v1") def multiplied_number(versioned_number): return versioned_number * 2
Once again, both assets have labels to indicate the change in the code version. Dagster doesn't know that v5 of the versioned number will return the same value as v4, as it only knows about code versions and data versions.
Let's see what happens if only versioned_number is materialized. Select it in the asset graph and click Materialize selected. The sidebar shows the latest materialization now has a code_version of v5, and the data version is again 20:
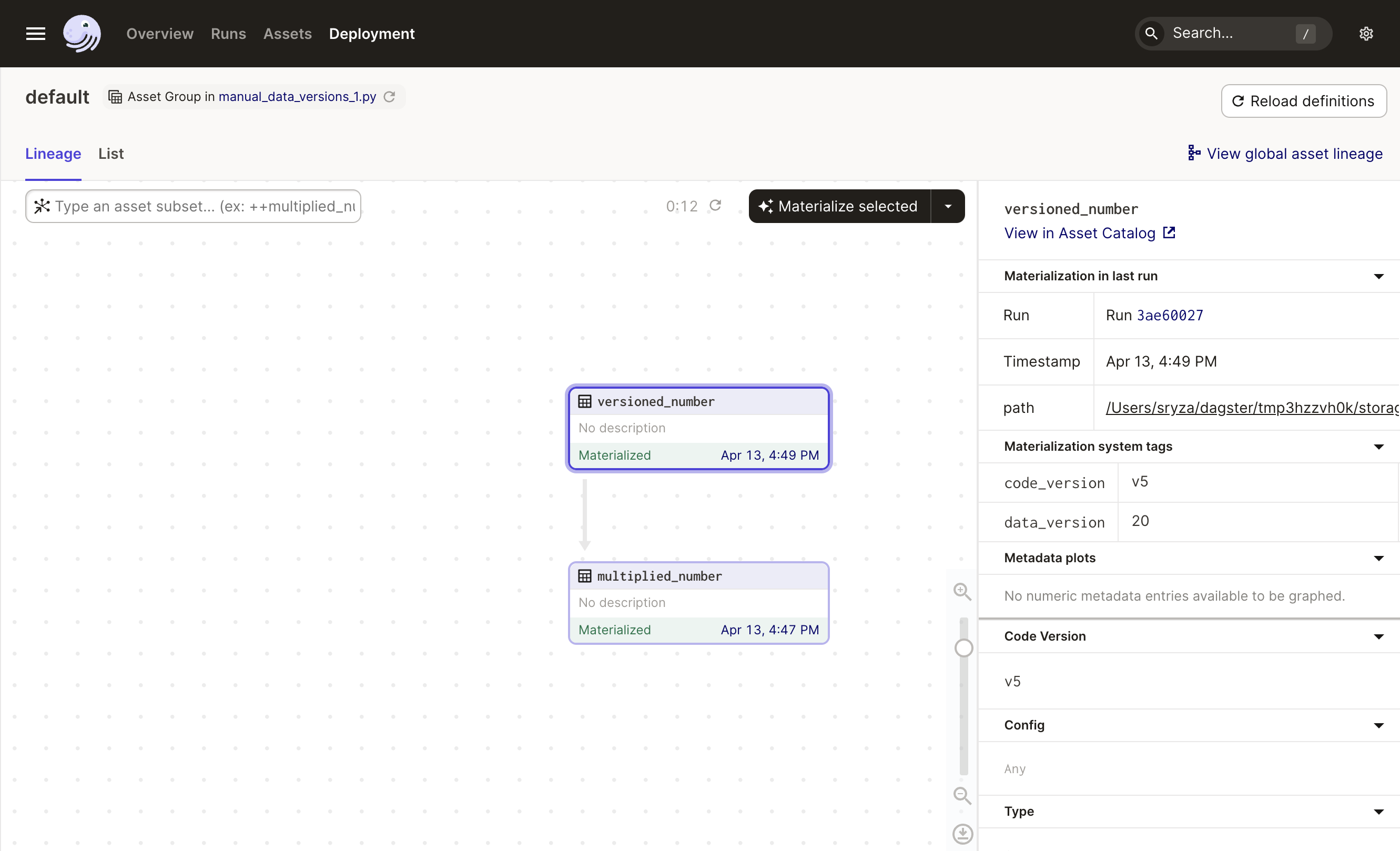
Notice that multiplied_number no longer has a label, even though we didn't materialize it! Here's what happened: the new materialization of versioned_number with the explicitly supplied data version supersedes the code version of versioned_number. Dagster then compared the data version of versioned_number last used to materialize multiplied_number to the current data version of versioned_number. Since this comparison shows that the data version of versioned_number hasn't changed, Dagster knows that the change to the code version of versioned_number doesn't affect multiplied_number.
If versioned_number had used a Dagster-generated data version, the data version of versioned_number would have changed due to its updated code version despite the fact that the returned value did not change. multiplied_number would have a label indicating that an upstream data version had changed.
Step four: data versions with source assets#
In the real world, data pipelines depend on external upstream data. So far in this guide, we haven't used any external data; we've been substituting hardcoded data in the asset at the root of our graph and using a code version as a stand-in for the version of that data. We can do better than this.
External data sources in Dagster are modeled by SourceAssets. We can add versioning to a SourceAsset by making it observable. An observable source asset has a user-defined function that computes and returns a data version.
Let's add an @observable_source_asset called input_number. This will represent a file written by an external process upstream of our pipeline:
29034
The body of the input_number function computes a hash of the file contents and returns it as a DataVersion. We'll set input_number as an upstream dependency of versioned_number and have versioned_number return the value it reads from the file:
from hashlib import sha256 from dagster import ( DataVersion, Output, asset, file_relative_path, observable_source_asset, ) def sha256_digest_from_str(string: str) -> str: hash_sig = sha256() hash_sig.update(bytearray(string, "utf8")) return hash_sig.hexdigest() FILE_PATH = file_relative_path(__file__, "input_number.txt") @observable_source_asset def input_number(): with open(FILE_PATH) as ff: return DataVersion(sha256_digest_from_str(ff.read())) @asset(code_version="v6", deps=[input_number]) def versioned_number(): with open(FILE_PATH) as ff: value = int(ff.read()) return Output(value, data_version=DataVersion(str(value))) @asset(code_version="v1") def multiplied_number(versioned_number): return versioned_number * 2
Adding an observable source asset to an asset graph will cause a new button, Observe sources, to appear:
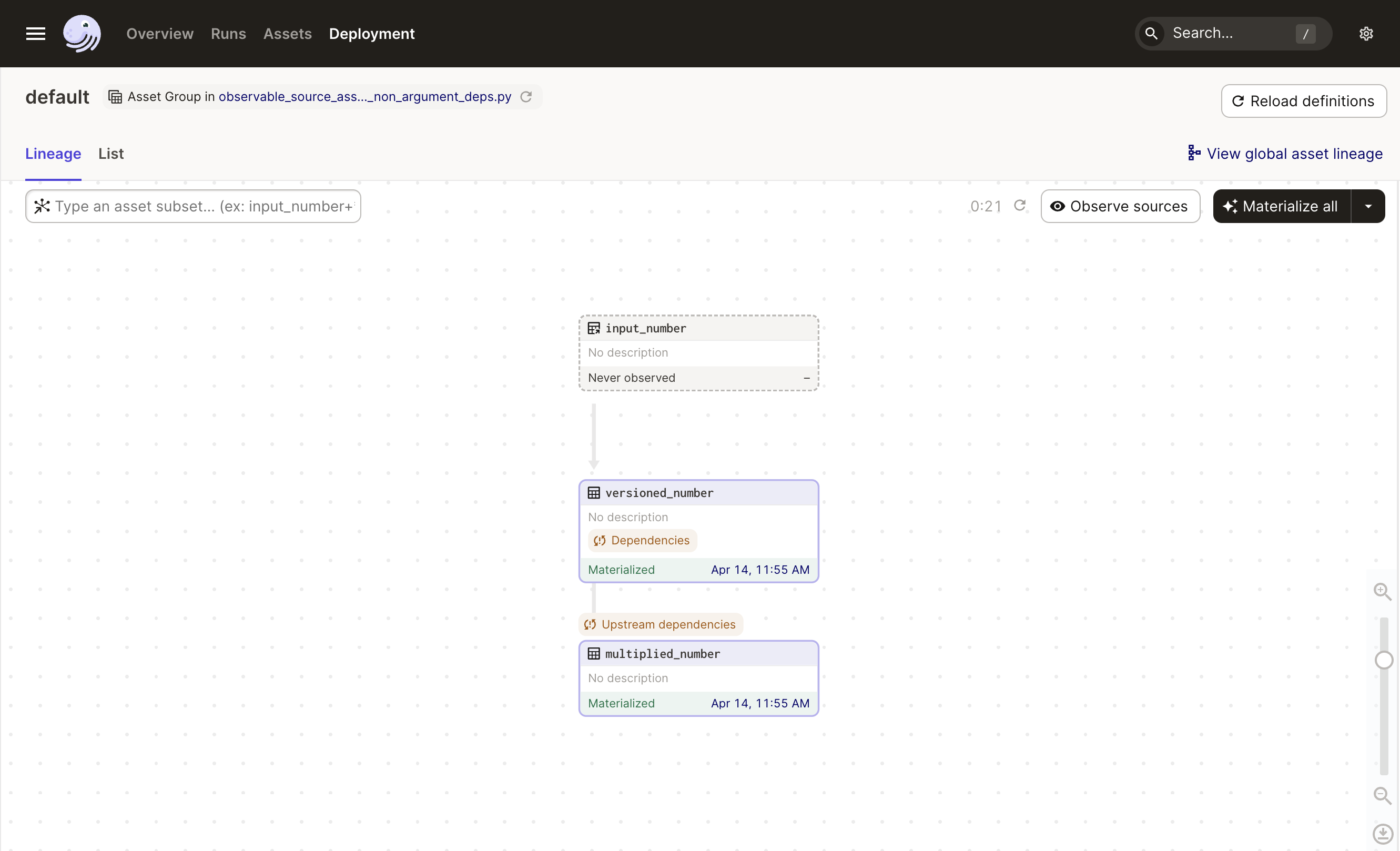
Click this button to kick off a run that executes the observation function of input_number. Let's look at the entry in the asset catalog for input_number:
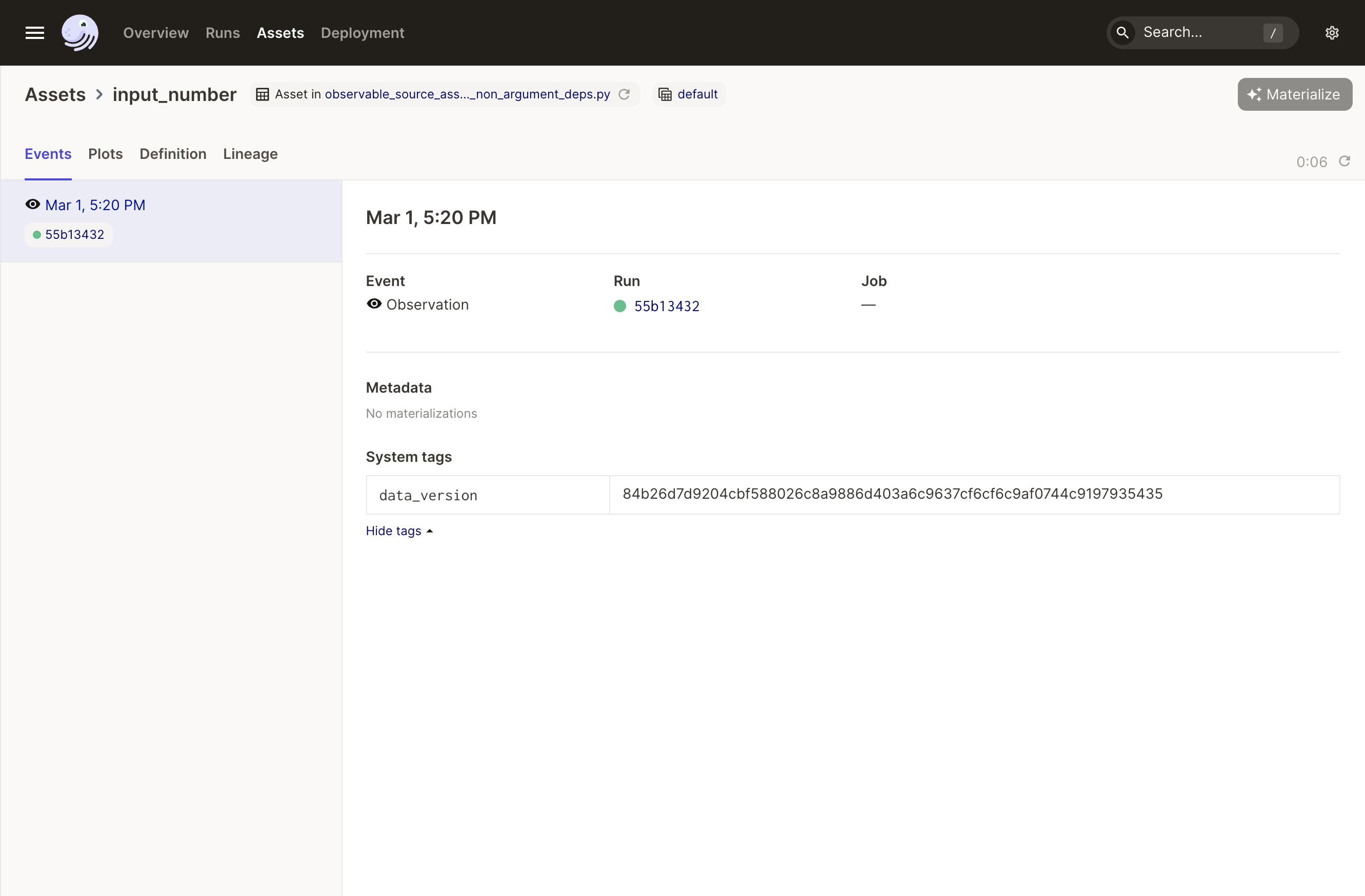
Take note of the data_version listed here that you computed.
We also see that versioned_number and multiplied_number have labels indicating that they have new upstream dependencies (because we added the observable source asset to the graph). Click Materialize all to bring them up to date.
Finally, let's manually alter the file to simulate the activity of an external process. Change the content of input_number.txt:
15397
If we click the Observe Sources button again, the downstream assets will again have labels indicating that upstream data has changed. The observation run generated a new data version for input_number because its content changed.